 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBendVLM: Test-Time Debiasing of Vision-Language Embeddings
Nov 07, 2024



Vision-language model (VLM) embeddings have been shown to encode biases present in their training data, such as societal biases that prescribe negative characteristics to members of various racial and gender identities. VLMs are being quickly adopted for a variety of tasks ranging from few-shot classification to text-guided image generation, making debiasing VLM embeddings crucial. Debiasing approaches that fine-tune the VLM often suffer from catastrophic forgetting. On the other hand, fine-tuning-free methods typically utilize a "one-size-fits-all" approach that assumes that correlation with the spurious attribute can be explained using a single linear direction across all possible inputs. In this work, we propose Bend-VLM, a nonlinear, fine-tuning-free approach for VLM embedding debiasing that tailors the debiasing operation to each unique input. This allows for a more flexible debiasing approach. Additionally, we do not require knowledge of the set of inputs a priori to inference time, making our method more appropriate for online, open-set tasks such as retrieval and text guided image generation.
Identifying Implicit Social Biases in Vision-Language Models
Nov 01, 2024Vision-language models, like CLIP (Contrastive Language Image Pretraining), are becoming increasingly popular for a wide range of multimodal retrieval tasks. However, prior work has shown that large language and deep vision models can learn historical biases contained in their training sets, leading to perpetuation of stereotypes and potential downstream harm. In this work, we conduct a systematic analysis of the social biases that are present in CLIP, with a focus on the interaction between image and text modalities. We first propose a taxonomy of social biases called So-B-IT, which contains 374 words categorized across ten types of bias. Each type can lead to societal harm if associated with a particular demographic group. Using this taxonomy, we examine images retrieved by CLIP from a facial image dataset using each word as part of a prompt. We find that CLIP frequently displays undesirable associations between harmful words and specific demographic groups, such as retrieving mostly pictures of Middle Eastern men when asked to retrieve images of a "terrorist". Finally, we conduct an analysis of the source of such biases, by showing that the same harmful stereotypes are also present in a large image-text dataset used to train CLIP models for examples of biases that we find. Our findings highlight the importance of evaluating and addressing bias in vision-language models, and suggest the need for transparency and fairness-aware curation of large pre-training datasets.
Data Debiasing with Datamodels (D3M): Improving Subgroup Robustness via Data Selection
Jun 24, 2024Machine learning models can fail on subgroups that are underrepresented during training. While techniques such as dataset balancing can improve performance on underperforming groups, they require access to training group annotations and can end up removing large portions of the dataset. In this paper, we introduce Data Debiasing with Datamodels (D3M), a debiasing approach which isolates and removes specific training examples that drive the model's failures on minority groups. Our approach enables us to efficiently train debiased classifiers while removing only a small number of examples, and does not require training group annotations or additional hyperparameter tuning.
Selective Classification Via Neural Network Training Dynamics
May 26, 2022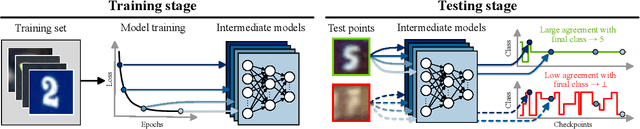
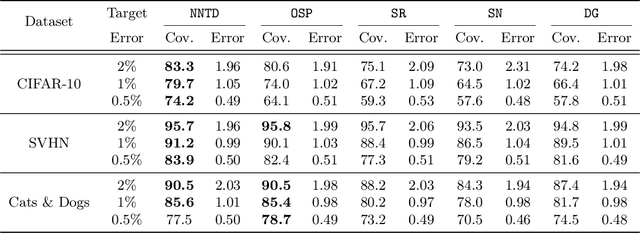
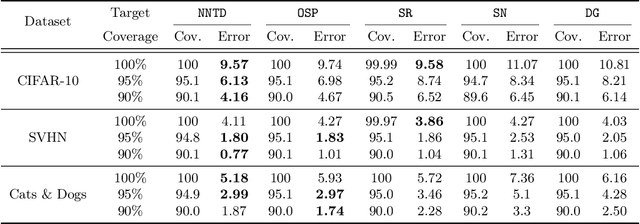
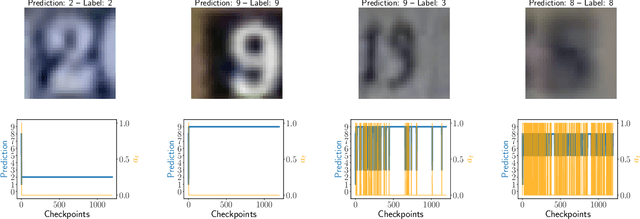
Selective classification is the task of rejecting inputs a model would predict incorrectly on through a trade-off between input space coverage and model accuracy. Current methods for selective classification impose constraints on either the model architecture or the loss function; this inhibits their usage in practice. In contrast to prior work, we show that state-of-the-art selective classification performance can be attained solely from studying the (discretized) training dynamics of a model. We propose a general framework that, for a given test input, monitors metrics capturing the disagreement with the final predicted label over intermediate models obtained during training; we then reject data points exhibiting too much disagreement at late stages in training. In particular, we instantiate a method that tracks when the label predicted during training stops disagreeing with the final predicted label. Our experimental evaluation shows that our method achieves state-of-the-art accuracy/coverage trade-offs on typical selective classification benchmarks. For example, we improve coverage on CIFAR-10/SVHN by 10.1%/1.5% respectively at a fixed target error of 0.5%.
The Road to Explainability is Paved with Bias: Measuring the Fairness of Explanations
May 06, 2022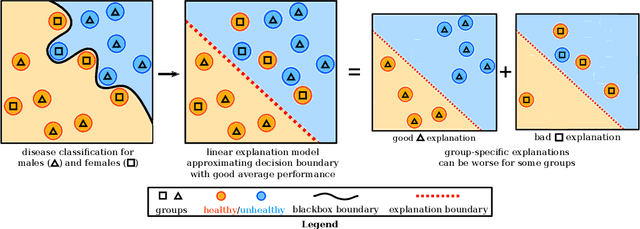
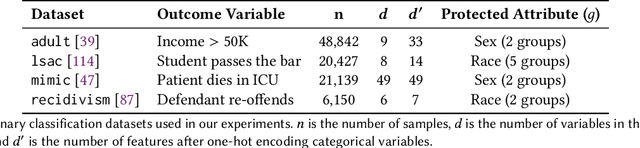
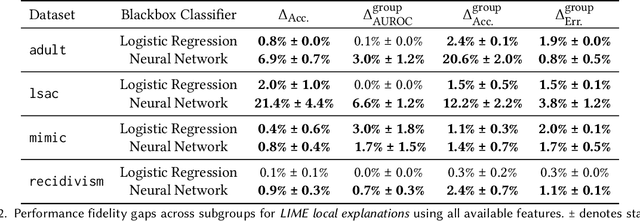
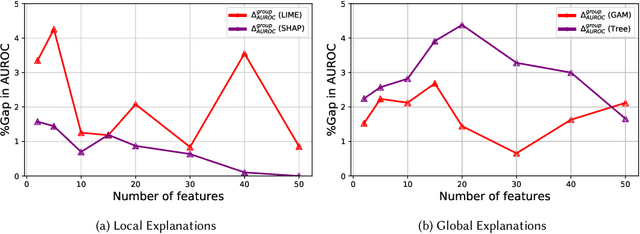
Machine learning models in safety-critical settings like healthcare are often blackboxes: they contain a large number of parameters which are not transparent to users. Post-hoc explainability methods where a simple, human-interpretable model imitates the behavior of these blackbox models are often proposed to help users trust model predictions. In this work, we audit the quality of such explanations for different protected subgroups using real data from four settings in finance, healthcare, college admissions, and the US justice system. Across two different blackbox model architectures and four popular explainability methods, we find that the approximation quality of explanation models, also known as the fidelity, differs significantly between subgroups. We also demonstrate that pairing explainability methods with recent advances in robust machine learning can improve explanation fairness in some settings. However, we highlight the importance of communicating details of non-zero fidelity gaps to users, since a single solution might not exist across all settings. Finally, we discuss the implications of unfair explanation models as a challenging and understudied problem facing the machine learning community.
Is Fairness Only Metric Deep? Evaluating and Addressing Subgroup Gaps in Deep Metric Learning
Mar 23, 2022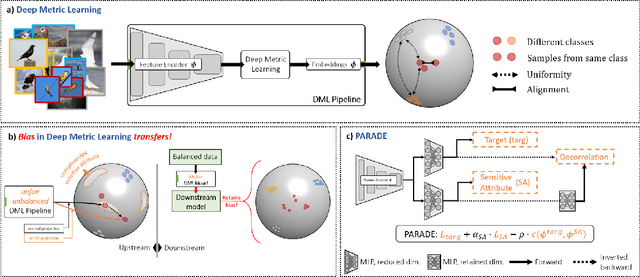
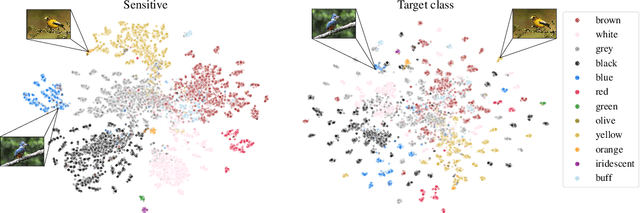
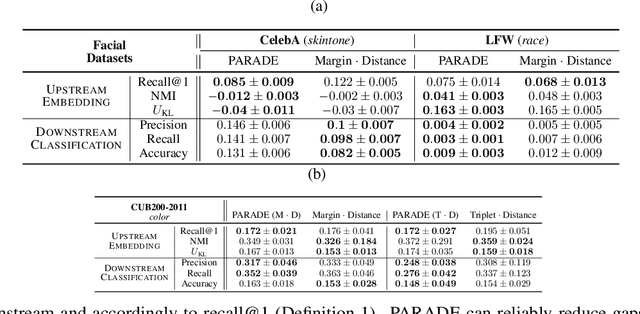
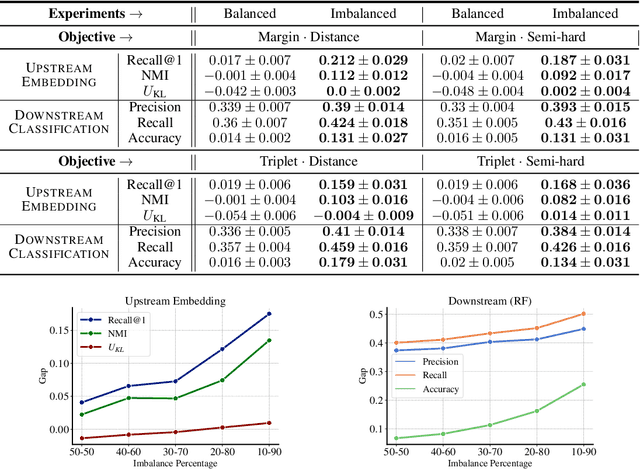
Deep metric learning (DML) enables learning with less supervision through its emphasis on the similarity structure of representations. There has been much work on improving generalization of DML in settings like zero-shot retrieval, but little is known about its implications for fairness. In this paper, we are the first to evaluate state-of-the-art DML methods trained on imbalanced data, and to show the negative impact these representations have on minority subgroup performance when used for downstream tasks. In this work, we first define fairness in DML through an analysis of three properties of the representation space -- inter-class alignment, intra-class alignment, and uniformity -- and propose finDML, the fairness in non-balanced DML benchmark to characterize representation fairness. Utilizing finDML, we find bias in DML representations to propagate to common downstream classification tasks. Surprisingly, this bias is propagated even when training data in the downstream task is re-balanced. To address this problem, we present Partial Attribute De-correlation (PARADE) to de-correlate feature representations from sensitive attributes and reduce performance gaps between subgroups in both embedding space and downstream metrics.