 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Classification Via Neural Network Training Dynamics
Paper and Code
May 26, 2022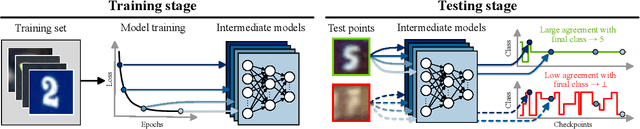
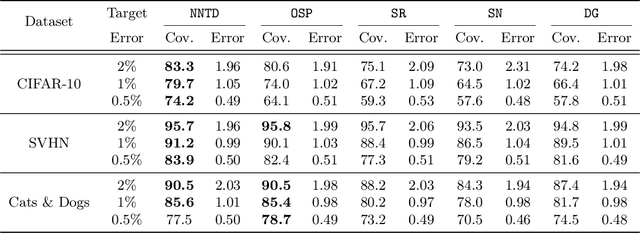
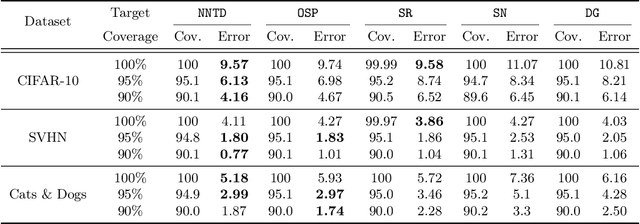
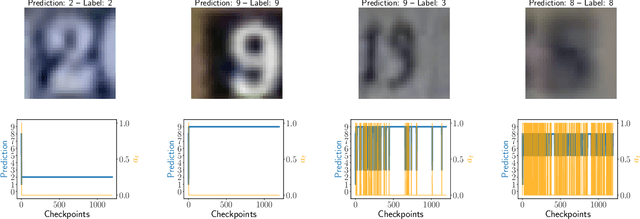
Selective classification is the task of rejecting inputs a model would predict incorrectly on through a trade-off between input space coverage and model accuracy. Current methods for selective classification impose constraints on either the model architecture or the loss function; this inhibits their usage in practice. In contrast to prior work, we show that state-of-the-art selective classification performance can be attained solely from studying the (discretized) training dynamics of a model. We propose a general framework that, for a given test input, monitors metrics capturing the disagreement with the final predicted label over intermediate models obtained during training; we then reject data points exhibiting too much disagreement at late stages in training. In particular, we instantiate a method that tracks when the label predicted during training stops disagreeing with the final predicted label. Our experimental evaluation shows that our method achieves state-of-the-art accuracy/coverage trade-offs on typical selective classification benchmarks. For example, we improve coverage on CIFAR-10/SVHN by 10.1%/1.5% respectively at a fixed target error of 0.5%.