 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Quality Dimensions as Interpretable Primitives for Speaking Style for Atypical Speech and Affect
May 27, 2025



Perceptual voice quality dimensions describe key characteristics of atypical speech and other speech modulations. Here we develop and evaluate voice quality models for seven voice and speech dimensions (intelligibility, imprecise consonants, harsh voice, naturalness, monoloudness, monopitch, and breathiness). Probes were trained on the public Speech Accessibility (SAP) project dataset with 11,184 samples from 434 speakers, using embeddings from frozen pre-trained models as features. We found that our probes had both strong performance and strong generalization across speech elicitation categories in the SAP dataset. We further validated zero-shot performance on additional datasets, encompassing unseen languages and tasks: Italian atypical speech, English atypical speech, and affective speech. The strong zero-shot performance and the interpretability of results across an array of evaluations suggests the utility of using voice quality dimensions in speaking style-related tasks.
Affect Models Have Weak Generalizability to Atypical Speech
Apr 22, 2025Speech and voice conditions can alter the acoustic properties of speech, which could impact the performance of paralinguistic models for affect for people with atypical speech. We evaluate publicly available models for recognizing categorical and dimensional affect from speech on a dataset of atypical speech, comparing results to datasets of typical speech. We investigate three dimensions of speech atypicality: intelligibility, which is related to pronounciation; monopitch, which is related to prosody, and harshness, which is related to voice quality. We look at (1) distributional trends of categorical affect predictions within the dataset, (2) distributional comparisons of categorical affect predictions to similar datasets of typical speech, and (3) correlation strengths between text and speech predictions for spontaneous speech for valence and arousal. We find that the output of affect models is significantly impacted by the presence and degree of speech atypicalities. For instance, the percentage of speech predicted as sad is significantly higher for all types and grades of atypical speech when compared to similar typical speech datasets. In a preliminary investigation on improving robustness for atypical speech, we find that fine-tuning models on pseudo-labeled atypical speech data improves performance on atypical speech without impacting performance on typical speech. Our results emphasize the need for broader training and evaluation datasets for speech emotion models, and for modeling approaches that are robust to voice and speech differences.
RelCon: Relative Contrastive Learning for a Motion Foundation Model for Wearable Data
Nov 27, 2024



We present RelCon, a novel self-supervised \textit{Rel}ative \textit{Con}trastive learning approach that uses a learnable distance measure in combination with a softened contrastive loss for training an motion foundation model from wearable sensors. The learnable distance measure captures motif similarity and domain-specific semantic information such as rotation invariance. The learned distance provides a measurement of semantic similarity between a pair of accelerometer time-series segments, which is used to measure the distance between an anchor and various other sampled candidate segments. The self-supervised model is trained on 1 billion segments from 87,376 participants from a large wearables dataset. The model achieves strong performance across multiple downstream tasks, encompassing both classification and regression. To our knowledge, we are the first to show the generalizability of a self-supervised learning model with motion data from wearables across distinct evaluation tasks.
Do LLMs "know" internally when they follow instructions?
Oct 22, 2024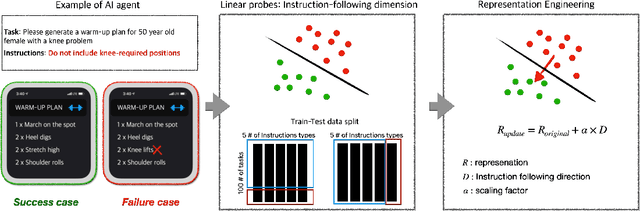


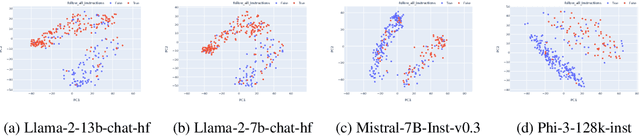
Instruction-following is crucial for building AI agents with large language models (LLMs), as these models must adhere strictly to user-provided constraints and guidelines. However, LLMs often fail to follow even simple and clear instructions. To improve instruction-following behavior and prevent undesirable outputs, a deeper understanding of how LLMs' internal states relate to these outcomes is required. Our analysis of LLM internal states reveal a dimension in the input embedding space linked to successful instruction-following. We demonstrate that modifying representations along this dimension improves instruction-following success rates compared to random changes, without compromising response quality. Further investigation reveals that this dimension is more closely related to the phrasing of prompts rather than the inherent difficulty of the task or instructions. This discovery also suggests explanations for why LLMs sometimes fail to follow clear instructions and why prompt engineering is often effective, even when the content remains largely unchanged. This work provides insight into the internal workings of LLMs' instruction-following, paving the way for reliable LLM agents.