 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Predictors under Distribution Shift
Paper and Code
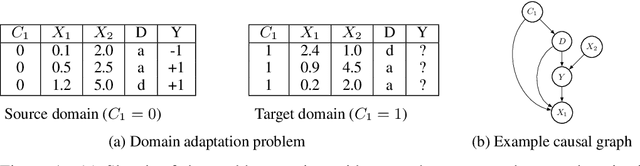


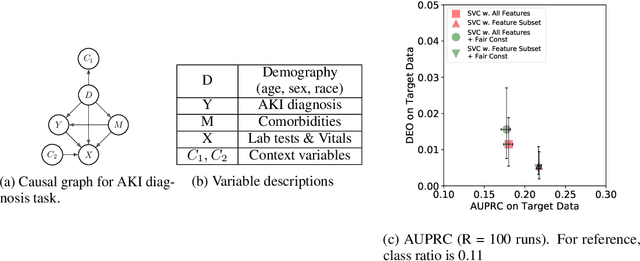
Recent work on fair machine learning adds to a growing set of algorithmic safeguards required for deployment in high societal impact areas. A fundamental concern with model deployment is to guarantee stable performance under changes in data distribution. Extensive work in domain adaptation addresses this concern, albeit with the notion of stability limited to that of predictive performance. We provide conditions under which a stable model both in terms of prediction and fairness performance can be trained. Building on the problem setup of causal domain adaptation, we select a subset of features for training predictors with fairness constraints such that risk with respect to an unseen target data distribution is minimized. Advantages of the approach are demonstrated on synthetic datasets and on the task of diagnosing acute kidney injury in a real-world dataset under an instance of measurement policy shift and selection bias.