 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening to the Wise Few: Select-and-Copy Attention Heads for Multiple-Choice QA
Paper and Code
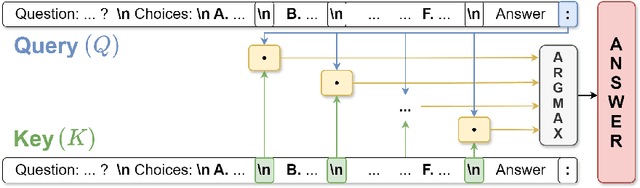
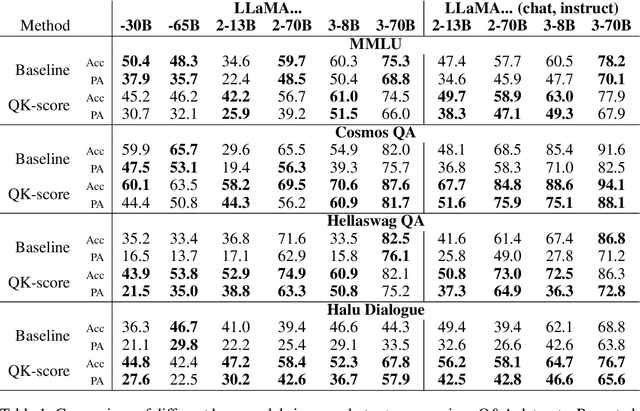
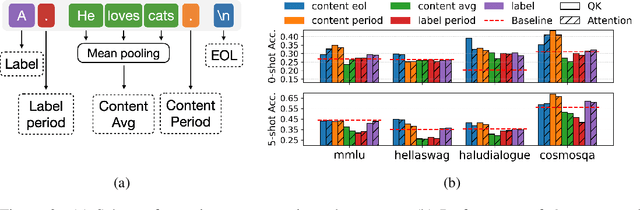
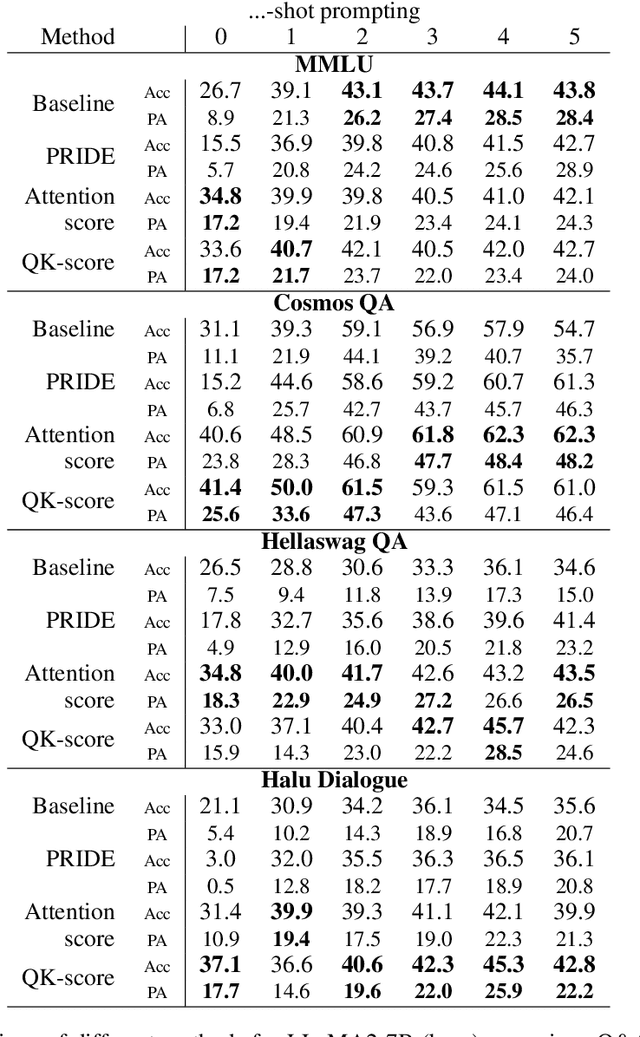
A standard way to evaluate the abilities of LLM involves presenting a multiple-choice question and selecting the option with the highest logit as the model's predicted answer. However, such a format for evaluating LLMs has limitations, since even if the model knows the correct answer, it may struggle to select the corresponding letter simply due to difficulties in following this rigid format. To address this, we introduce new scores that better capture and reveal model's underlying knowledge: the Query-Key Score (QK-score), derived from the interaction between query and key representations in attention heads, and the Attention Score, based on attention weights. These scores are extracted from specific \textit{select-and-copy} heads, which show consistent performance across popular Multi-Choice Question Answering (MCQA) datasets. Based on these scores, our method improves knowledge extraction, yielding up to 16\% gain for LLaMA2-7B and up to 10\% for larger models on popular MCQA benchmarks. At the same time, the accuracy on a simple synthetic dataset, where the model explicitly knows the right answer, increases by almost 60\%, achieving nearly perfect accuracy, therefore demonstrating the method's efficiency in mitigating MCQA format limitations. To support our claims, we conduct experiments on models ranging from 7 billion to 70 billion parameters in both zero- and few-shot setups.