 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindShift: Analyzing Language Models' Reactions to Psychological Prompts
Dec 18, 2025



Large language models (LLMs) hold the potential to absorb and reflect personality traits and attitudes specified by users. In our study, we investigated this potential using robust psychometric measures. We adapted the most studied test in psychological literature, namely Minnesota Multiphasic Personality Inventory (MMPI) and examined LLMs' behavior to identify traits. To asses the sensitivity of LLMs' prompts and psychological biases we created personality-oriented prompts, crafting a detailed set of personas that vary in trait intensity. This enables us to measure how well LLMs follow these roles. Our study introduces MindShift, a benchmark for evaluating LLMs' psychological adaptability. The results highlight a consistent improvement in LLMs' role perception, attributed to advancements in training datasets and alignment techniques. Additionally, we observe significant differences in responses to psychometric assessments across different model types and families, suggesting variability in their ability to emulate human-like personality traits. MindShift prompts and code for LLM evaluation will be publicly available.
I Have Covered All the Bases Here: Interpreting Reasoning Features in Large Language Models via Sparse Autoencoders
Mar 24, 2025Large Language Models (LLMs) have achieved remarkable success in natural language processing. Recent advances have led to the developing of a new class of reasoning LLMs; for example, open-source DeepSeek-R1 has achieved state-of-the-art performance by integrating deep thinking and complex reasoning. Despite these impressive capabilities, the internal reasoning mechanisms of such models remain unexplored. In this work, we employ Sparse Autoencoders (SAEs), a method to learn a sparse decomposition of latent representations of a neural network into interpretable features, to identify features that drive reasoning in the DeepSeek-R1 series of models. First, we propose an approach to extract candidate ''reasoning features'' from SAE representations. We validate these features through empirical analysis and interpretability methods, demonstrating their direct correlation with the model's reasoning abilities. Crucially, we demonstrate that steering these features systematically enhances reasoning performance, offering the first mechanistic account of reasoning in LLMs. Code available at https://github.com/AIRI-Institute/SAE-Reasoning
Feature-Level Insights into Artificial Text Detection with Sparse Autoencoders
Mar 05, 2025Artificial Text Detection (ATD) is becoming increasingly important with the rise of advanced Large Language Models (LLMs). Despite numerous efforts, no single algorithm performs consistently well across different types of unseen text or guarantees effective generalization to new LLMs. Interpretability plays a crucial role in achieving this goal. In this study, we enhance ATD interpretability by using Sparse Autoencoders (SAE) to extract features from Gemma-2-2b residual stream. We identify both interpretable and efficient features, analyzing their semantics and relevance through domain- and model-specific statistics, a steering approach, and manual or LLM-based interpretation. Our methods offer valuable insights into how texts from various models differ from human-written content. We show that modern LLMs have a distinct writing style, especially in information-dense domains, even though they can produce human-like outputs with personalized prompts.
LLM-Microscope: Uncovering the Hidden Role of Punctuation in Context Memory of Transformers
Feb 20, 2025We introduce methods to quantify how Large Language Models (LLMs) encode and store contextual information, revealing that tokens often seen as minor (e.g., determiners, punctuation) carry surprisingly high context. Notably, removing these tokens -- especially stopwords, articles, and commas -- consistently degrades performance on MMLU and BABILong-4k, even if removing only irrelevant tokens. Our analysis also shows a strong correlation between contextualization and linearity, where linearity measures how closely the transformation from one layer's embeddings to the next can be approximated by a single linear mapping. These findings underscore the hidden importance of filler tokens in maintaining context. For further exploration, we present LLM-Microscope, an open-source toolkit that assesses token-level nonlinearity, evaluates contextual memory, visualizes intermediate layer contributions (via an adapted Logit Lens), and measures the intrinsic dimensionality of representations. This toolkit illuminates how seemingly trivial tokens can be critical for long-range understanding.
Universal Adversarial Attack on Aligned Multimodal LLMs
Feb 11, 2025We propose a universal adversarial attack on multimodal Large Language Models (LLMs) that leverages a single optimized image to override alignment safeguards across diverse queries and even multiple models. By backpropagating through the vision encoder and language head, we craft a synthetic image that forces the model to respond with a targeted phrase (e.g., ''Sure, here it is'') or otherwise unsafe content-even for harmful prompts. In experiments on the SafeBench benchmark, our method achieves significantly higher attack success rates than existing baselines, including text-only universal prompts (e.g., up to 93% on certain models). We further demonstrate cross-model transferability by training on several multimodal LLMs simultaneously and testing on unseen architectures. Additionally, a multi-answer variant of our approach produces more natural-sounding (yet still malicious) responses. These findings underscore critical vulnerabilities in current multimodal alignment and call for more robust adversarial defenses. We will release code and datasets under the Apache-2.0 license. Warning: some content generated by Multimodal LLMs in this paper may be offensive to some readers.
Neglectable effect of brain MRI data prepreprocessing for tumor segmentation
Apr 11, 2022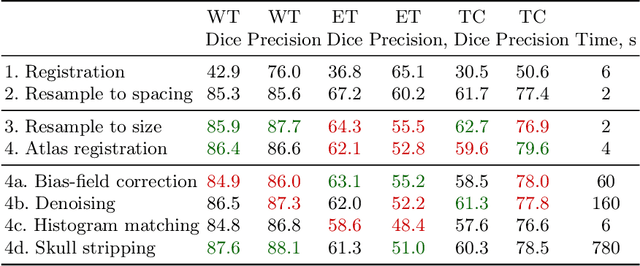
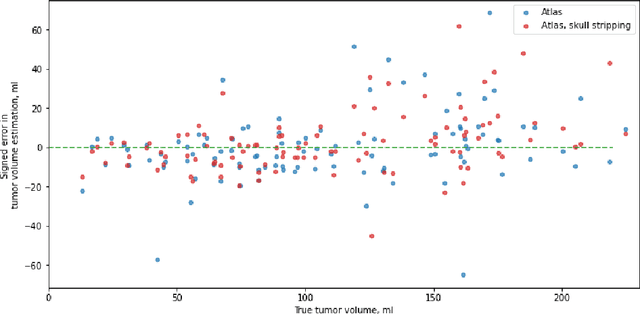

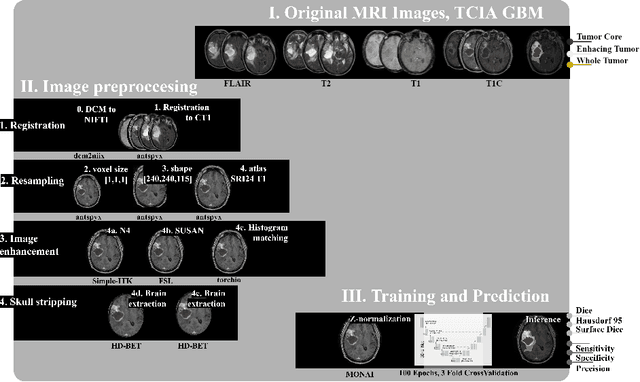
Magnetic resonance imaging (MRI) data is heterogeneous due to the differences in device manufacturers, scanning protocols, and inter-subject variability. A conventional way to mitigate MR image heterogeneity is to apply preprocessing transformations, such as anatomy alignment, voxel resampling, signal intensity equalization, image denoising, and localization of regions of interest (ROI). Although preprocessing pipeline standardizes image appearance, its influence on the quality of image segmentation and other downstream tasks on deep neural networks (DNN) has never been rigorously studied. Here we report a comprehensive study of multimodal MRI brain cancer image segmentation on TCIA-GBM open-source dataset. Our results demonstrate that most popular standardization steps add no value to artificial neural network performance; moreover, preprocessing can hamper model performance. We suggest that image intensity normalization approaches do not contribute to model accuracy because of the reduction of signal variance with image standardization. Finally, we show the contribution of scull-stripping in data preprocessing is almost negligible if measured in terms of clinically relevant metrics. We show that the only essential transformation for accurate analysis is the unification of voxel spacing across the dataset. In contrast, anatomy alignment in form of non-rigid atlas registration is not necessary and most intensity equalization steps do not improve model productiveness.