 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting Black-Box Face Recognition Systems via Zero-Order Optimization in Eigenface Space
Jun 11, 2025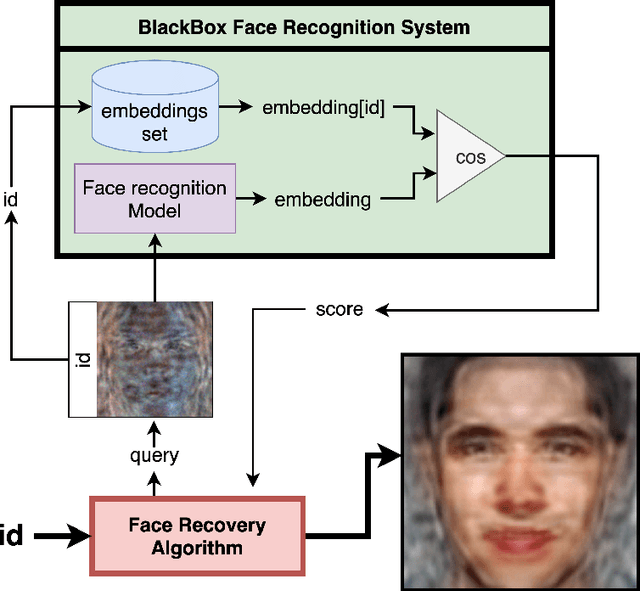

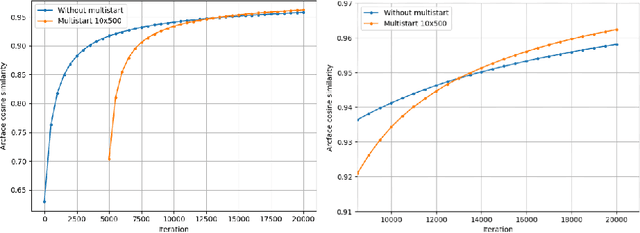
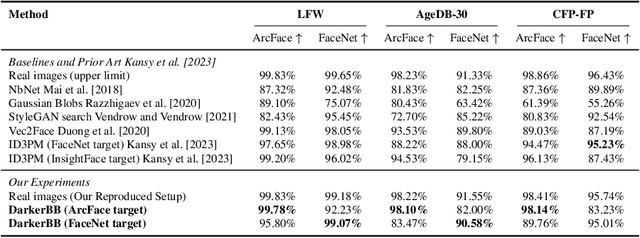
Reconstructing facial images from black-box recognition models poses a significant privacy threat. While many methods require access to embeddings, we address the more challenging scenario of model inversion using only similarity scores. This paper introduces DarkerBB, a novel approach that reconstructs color faces by performing zero-order optimization within a PCA-derived eigenface space. Despite this highly limited information, experiments on LFW, AgeDB-30, and CFP-FP benchmarks demonstrate that DarkerBB achieves state-of-the-art verification accuracies in the similarity-only setting, with competitive query efficiency.
LLM-Microscope: Uncovering the Hidden Role of Punctuation in Context Memory of Transformers
Feb 20, 2025We introduce methods to quantify how Large Language Models (LLMs) encode and store contextual information, revealing that tokens often seen as minor (e.g., determiners, punctuation) carry surprisingly high context. Notably, removing these tokens -- especially stopwords, articles, and commas -- consistently degrades performance on MMLU and BABILong-4k, even if removing only irrelevant tokens. Our analysis also shows a strong correlation between contextualization and linearity, where linearity measures how closely the transformation from one layer's embeddings to the next can be approximated by a single linear mapping. These findings underscore the hidden importance of filler tokens in maintaining context. For further exploration, we present LLM-Microscope, an open-source toolkit that assesses token-level nonlinearity, evaluates contextual memory, visualizes intermediate layer contributions (via an adapted Logit Lens), and measures the intrinsic dimensionality of representations. This toolkit illuminates how seemingly trivial tokens can be critical for long-range understanding.
Universal Adversarial Attack on Aligned Multimodal LLMs
Feb 11, 2025We propose a universal adversarial attack on multimodal Large Language Models (LLMs) that leverages a single optimized image to override alignment safeguards across diverse queries and even multiple models. By backpropagating through the vision encoder and language head, we craft a synthetic image that forces the model to respond with a targeted phrase (e.g., ''Sure, here it is'') or otherwise unsafe content-even for harmful prompts. In experiments on the SafeBench benchmark, our method achieves significantly higher attack success rates than existing baselines, including text-only universal prompts (e.g., up to 93% on certain models). We further demonstrate cross-model transferability by training on several multimodal LLMs simultaneously and testing on unseen architectures. Additionally, a multi-answer variant of our approach produces more natural-sounding (yet still malicious) responses. These findings underscore critical vulnerabilities in current multimodal alignment and call for more robust adversarial defenses. We will release code and datasets under the Apache-2.0 license. Warning: some content generated by Multimodal LLMs in this paper may be offensive to some readers.
Your Transformer is Secretly Linear
May 19, 2024



This paper reveals a novel linear characteristic exclusive to transformer decoders, including models such as GPT, LLaMA, OPT, BLOOM and others. We analyze embedding transformations between sequential layers, uncovering a near-perfect linear relationship (Procrustes similarity score of 0.99). However, linearity decreases when the residual component is removed due to a consistently low output norm of the transformer layer. Our experiments show that removing or linearly approximating some of the most linear blocks of transformers does not affect significantly the loss or model performance. Moreover, in our pretraining experiments on smaller models we introduce a cosine-similarity-based regularization, aimed at reducing layer linearity. This regularization improves performance metrics on benchmarks like Tiny Stories and SuperGLUE and as well successfully decreases the linearity of the models. This study challenges the existing understanding of transformer architectures, suggesting that their operation may be more linear than previously assumed.
OmniFusion Technical Report
Apr 09, 2024



Last year, multimodal architectures served up a revolution in AI-based approaches and solutions, extending the capabilities of large language models (LLM). We propose an \textit{OmniFusion} model based on a pretrained LLM and adapters for visual modality. We evaluated and compared several architecture design principles for better text and visual data coupling: MLP and transformer adapters, various CLIP ViT-based encoders (SigLIP, InternVIT, etc.), and their fusing approach, image encoding method (whole image or tiles encoding) and two 7B LLMs (the proprietary one and open-source Mistral). Experiments on 8 visual-language benchmarks show the top score for the best OmniFusion setup in terms of different VQA tasks in comparison with open-source LLaVA-like solutions: VizWiz, Pope, MM-Vet, ScienceQA, MMBench, TextVQA, VQAv2, MMMU. We also propose a variety of situations, where OmniFusion provides highly-detailed answers in different domains: housekeeping, sightseeing, culture, medicine, handwritten and scanned equations recognition, etc. Mistral-based OmniFusion model is an open-source solution with weights, training and inference scripts available at https://github.com/AIRI-Institute/OmniFusion.
The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models
Nov 10, 2023In this study, we present an investigation into the anisotropy dynamics and intrinsic dimension of embeddings in transformer architectures, focusing on the dichotomy between encoders and decoders. Our findings reveal that the anisotropy profile in transformer decoders exhibits a distinct bell-shaped curve, with the highest anisotropy concentrations in the middle layers. This pattern diverges from the more uniformly distributed anisotropy observed in encoders. In addition, we found that the intrinsic dimension of embeddings increases in the initial phases of training, indicating an expansion into higher-dimensional space. Which is then followed by a compression phase towards the end of training with dimensionality decrease, suggesting a refinement into more compact representations. Our results provide fresh insights to the understanding of encoders and decoders embedding properties.