 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent State Encoders for Efficient Neural Combinatorial Optimization
Sep 05, 2025The primary paradigm in Neural Combinatorial Optimization (NCO) are construction methods, where a neural network is trained to sequentially add one solution component at a time until a complete solution is constructed. We observe that the typical changes to the state between two steps are small, since usually only the node that gets added to the solution is removed from the state. An efficient model should be able to reuse computation done in prior steps. To that end, we propose to train a recurrent encoder that computes the state embeddings not only based on the state but also the embeddings of the step before. We show that the recurrent encoder can achieve equivalent or better performance than a non-recurrent encoder even if it consists of $3\times$ fewer layers, thus significantly improving on latency. We demonstrate our findings on three different problems: the Traveling Salesman Problem (TSP), the Capacitated Vehicle Routing Problem (CVRP), and the Orienteering Problem (OP) and integrate the models into a large neighborhood search algorithm, to showcase the practical relevance of our findings.
IMTS-Mixer: Mixer-Networks for Irregular Multivariate Time Series Forecasting
Feb 17, 2025Forecasting Irregular Multivariate Time Series (IMTS) has recently emerged as a distinct research field, necessitating specialized models to address its unique challenges. While most forecasting literature assumes regularly spaced observations without missing values, many real-world datasets - particularly in healthcare, climate research, and biomechanics - violate these assumptions. Time Series (TS)-mixer models have achieved remarkable success in regular multivariate time series forecasting. However, they remain unexplored for IMTS due to their requirement for complete and evenly spaced observations. To bridge this gap, we introduce IMTS-Mixer, a novel forecasting architecture designed specifically for IMTS. Our approach retains the core principles of TS mixer models while introducing innovative methods to transform IMTS into fixed-size matrix representations, enabling their seamless integration with mixer modules. We evaluate IMTS-Mixer on a benchmark of four real-world datasets from various domains. Our results demonstrate that IMTS-Mixer establishes a new state-of-the-art in forecasting accuracy while also improving computational efficiency.
Moco: A Learnable Meta Optimizer for Combinatorial Optimization
Feb 09, 2024Relevant combinatorial optimization problems (COPs) are often NP-hard. While they have been tackled mainly via handcrafted heuristics in the past, advances in neural networks have motivated the development of general methods to learn heuristics from data. Many approaches utilize a neural network to directly construct a solution, but are limited in further improving based on already constructed solutions at inference time. Our approach, Moco, learns a graph neural network that updates the solution construction procedure based on features extracted from the current search state. This meta training procedure targets the overall best solution found during the search procedure given information such as the search budget. This allows Moco to adapt to varying circumstances such as different computational budgets. Moco is a fully learnable meta optimizer that does not utilize any problem specific local search or decomposition. We test Moco on the Traveling Salesman Problem (TSP) and Maximum Independent Set (MIS) and show that it outperforms other approaches on MIS and is overall competitive on the TSP, especially outperforming related approaches, partially even if they use additional local search.
Routing Arena: A Benchmark Suite for Neural Routing Solvers
Oct 06, 2023Neural Combinatorial Optimization has been researched actively in the last eight years. Even though many of the proposed Machine Learning based approaches are compared on the same datasets, the evaluation protocol exhibits essential flaws and the selection of baselines often neglects State-of-the-Art Operations Research approaches. To improve on both of these shortcomings, we propose the Routing Arena, a benchmark suite for Routing Problems that provides a seamless integration of consistent evaluation and the provision of baselines and benchmarks prevalent in the Machine Learning- and Operations Research field. The proposed evaluation protocol considers the two most important evaluation cases for different applications: First, the solution quality for an a priori fixed time budget and secondly the anytime performance of the respective methods. By setting the solution trajectory in perspective to a Best Known Solution and a Base Solver's solutions trajectory, we furthermore propose the Weighted Relative Average Performance (WRAP), a novel evaluation metric that quantifies the often claimed runtime efficiency of Neural Routing Solvers. A comprehensive first experimental evaluation demonstrates that the most recent Operations Research solvers generate state-of-the-art results in terms of solution quality and runtime efficiency when it comes to the vehicle routing problem. Nevertheless, some findings highlight the advantages of neural approaches and motivate a shift in how neural solvers should be conceptualized.
RP-DQN: An application of Q-Learning to Vehicle Routing Problems
Apr 25, 2021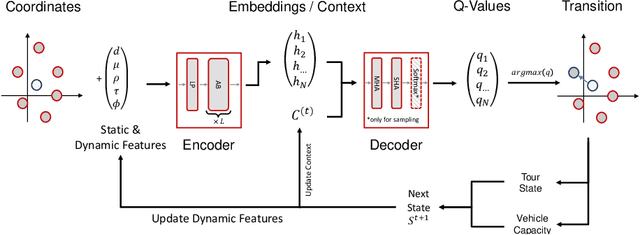
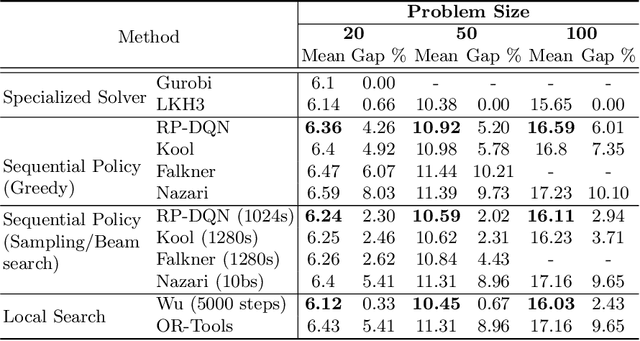
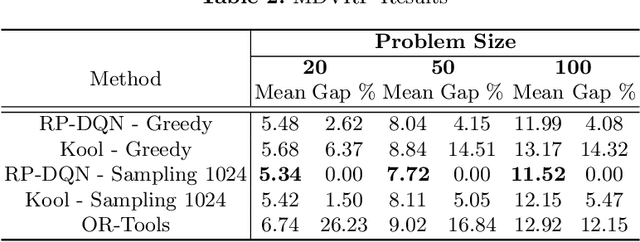
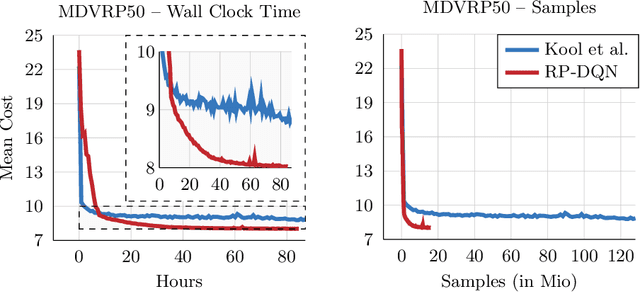
In this paper we present a new approach to tackle complex routing problems with an improved state representation that utilizes the model complexity better than previous methods. We enable this by training from temporal differences. Specifically Q-Learning is employed. We show that our approach achieves state-of-the-art performance for autoregressive policies that sequentially insert nodes to construct solutions on the CVRP. Additionally, we are the first to tackle the MDVRP with machine learning methods and demonstrate that this problem type greatly benefits from our approach over other ML methods.