 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting Arena: A Benchmark Suite for Neural Routing Solvers
Oct 06, 2023Neural Combinatorial Optimization has been researched actively in the last eight years. Even though many of the proposed Machine Learning based approaches are compared on the same datasets, the evaluation protocol exhibits essential flaws and the selection of baselines often neglects State-of-the-Art Operations Research approaches. To improve on both of these shortcomings, we propose the Routing Arena, a benchmark suite for Routing Problems that provides a seamless integration of consistent evaluation and the provision of baselines and benchmarks prevalent in the Machine Learning- and Operations Research field. The proposed evaluation protocol considers the two most important evaluation cases for different applications: First, the solution quality for an a priori fixed time budget and secondly the anytime performance of the respective methods. By setting the solution trajectory in perspective to a Best Known Solution and a Base Solver's solutions trajectory, we furthermore propose the Weighted Relative Average Performance (WRAP), a novel evaluation metric that quantifies the often claimed runtime efficiency of Neural Routing Solvers. A comprehensive first experimental evaluation demonstrates that the most recent Operations Research solvers generate state-of-the-art results in terms of solution quality and runtime efficiency when it comes to the vehicle routing problem. Nevertheless, some findings highlight the advantages of neural approaches and motivate a shift in how neural solvers should be conceptualized.
Too Big, so Fail? -- Enabling Neural Construction Methods to Solve Large-Scale Routing Problems
Sep 29, 2023



In recent years new deep learning approaches to solve combinatorial optimization problems, in particular NP-hard Vehicle Routing Problems (VRP), have been proposed. The most impactful of these methods are sequential neural construction approaches which are usually trained via reinforcement learning. Due to the high training costs of these models, they usually are trained on limited instance sizes (e.g. serving 100 customers) and later applied to vastly larger instance size (e.g. 2000 customers). By means of a systematic scale-up study we show that even state-of-the-art neural construction methods are outperformed by simple heuristics, failing to generalize to larger problem instances. We propose to use the ruin recreate principle that alternates between completely destroying a localized part of the solution and then recreating an improved variant. In this way, neural construction methods like POMO are never applied to the global problem but just in the reconstruction step, which only involves partial problems much closer in size to their original training instances. In thorough experiments on four datasets of varying distributions and modalities we show that our neural ruin recreate approach outperforms alternative forms of improving construction methods such as sampling and beam search and in several experiments also advanced local search approaches.
Neural Capacitated Clustering
Feb 10, 2023Recent work on deep clustering has found new promising methods also for constrained clustering problems. Their typically pairwise constraints often can be used to guide the partitioning of the data. Many problems however, feature cluster-level constraints, e.g. the Capacitated Clustering Problem (CCP), where each point has a weight and the total weight sum of all points in each cluster is bounded by a prescribed capacity. In this paper we propose a new method for the CCP, Neural Capacited Clustering, that learns a neural network to predict the assignment probabilities of points to cluster centers from a data set of optimal or near optimal past solutions of other problem instances. During inference, the resulting scores are then used in an iterative k-means like procedure to refine the assignment under capacity constraints. In our experiments on artificial data and two real world datasets our approach outperforms several state-of-the-art mathematical and heuristic solvers from the literature. Moreover, we apply our method in the context of a cluster-first-route-second approach to the Capacitated Vehicle Routing Problem (CVRP) and show competitive results on the well-known Uchoa benchmark.
Attention, Filling in The Gaps for Generalization in Routing Problems
Jul 14, 2022
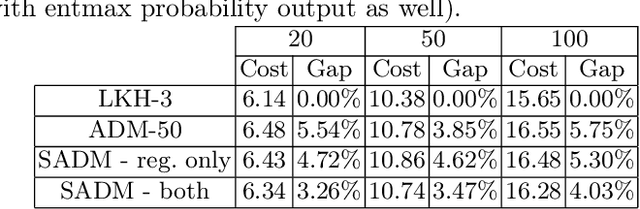
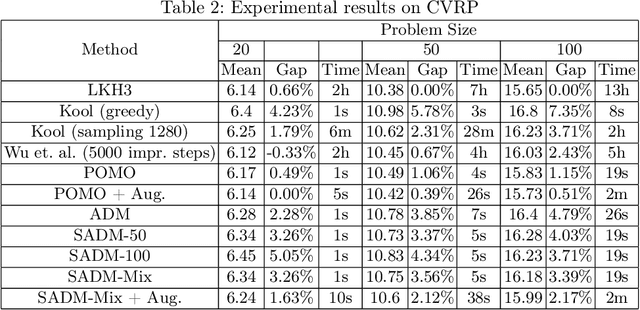
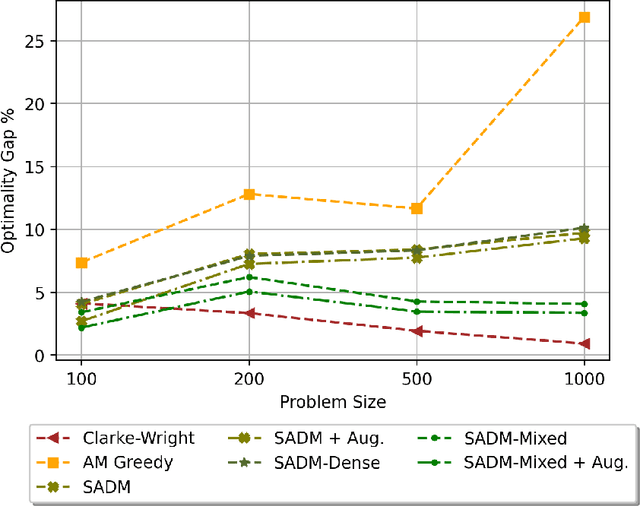
Machine Learning (ML) methods have become a useful tool for tackling vehicle routing problems, either in combination with popular heuristics or as standalone models. However, current methods suffer from poor generalization when tackling problems of different sizes or different distributions. As a result, ML in vehicle routing has witnessed an expansion phase with new methodologies being created for particular problem instances that become infeasible at larger problem sizes. This paper aims at encouraging the consolidation of the field through understanding and improving current existing models, namely the attention model by Kool et al. We identify two discrepancy categories for VRP generalization. The first is based on the differences that are inherent to the problems themselves, and the second relates to architectural weaknesses that limit the model's ability to generalize. Our contribution becomes threefold: We first target model discrepancies by adapting the Kool et al. method and its loss function for Sparse Dynamic Attention based on the alpha-entmax activation. We then target inherent differences through the use of a mixed instance training method that has been shown to outperform single instance training in certain scenarios. Finally, we introduce a framework for inference level data augmentation that improves performance by leveraging the model's lack of invariance to rotation and dilation changes.
Solving the Traveling Salesperson Problem with Precedence Constraints by Deep Reinforcement Learning
Jul 04, 2022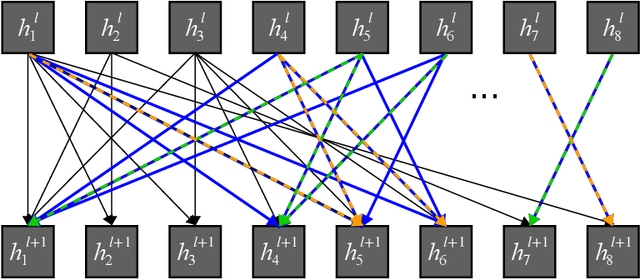
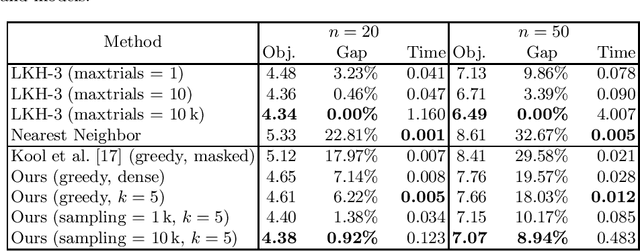
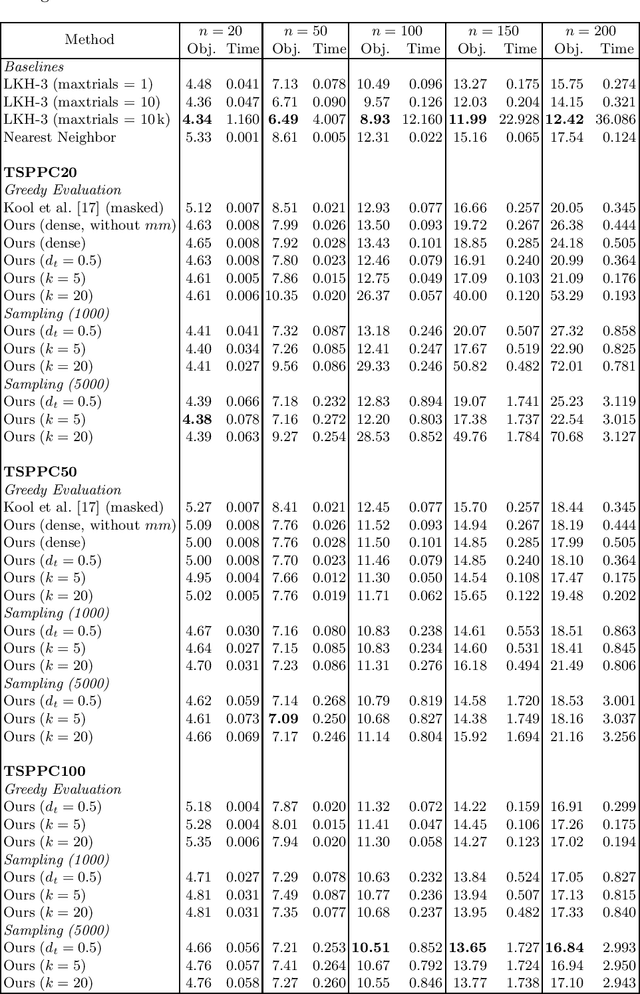
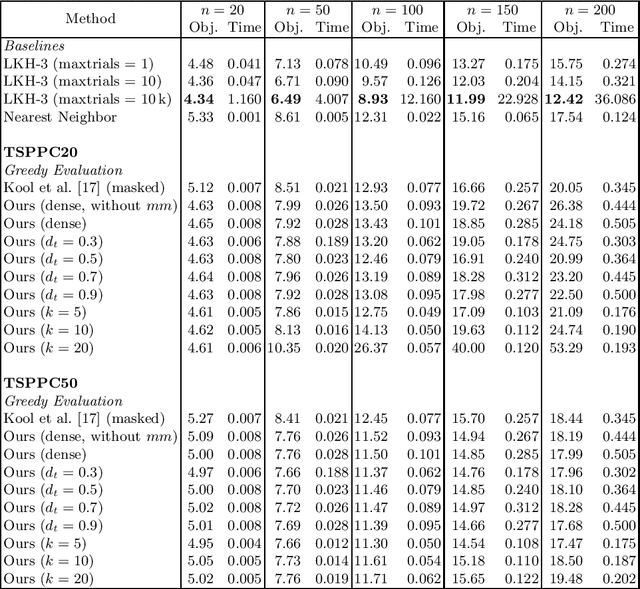
This work presents solutions to the Traveling Salesperson Problem with precedence constraints (TSPPC) using Deep Reinforcement Learning (DRL) by adapting recent approaches that work well for regular TSPs. Common to these approaches is the use of graph models based on multi-head attention (MHA) layers. One idea for solving the pickup and delivery problem (PDP) is using heterogeneous attentions to embed the different possible roles each node can take. In this work, we generalize this concept of heterogeneous attentions to the TSPPC. Furthermore, we adapt recent ideas to sparsify attentions for better scalability. Overall, we contribute to the research community through the application and evaluation of recent DRL methods in solving the TSPPC.
Learning to Control Local Search for Combinatorial Optimization
Jun 27, 2022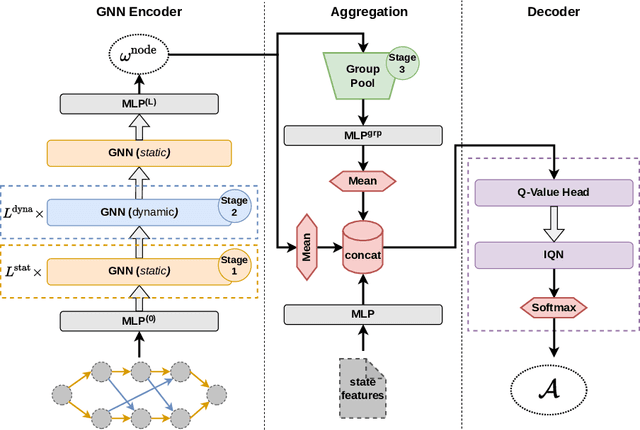
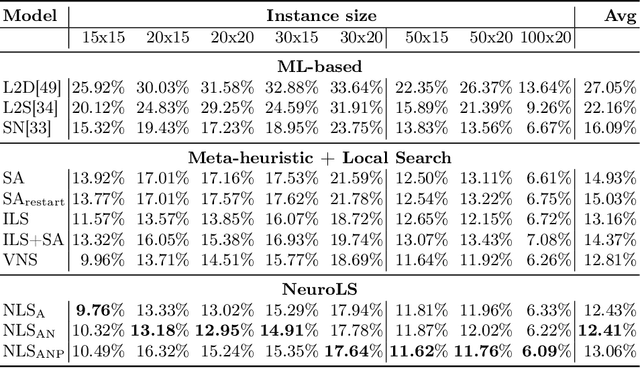
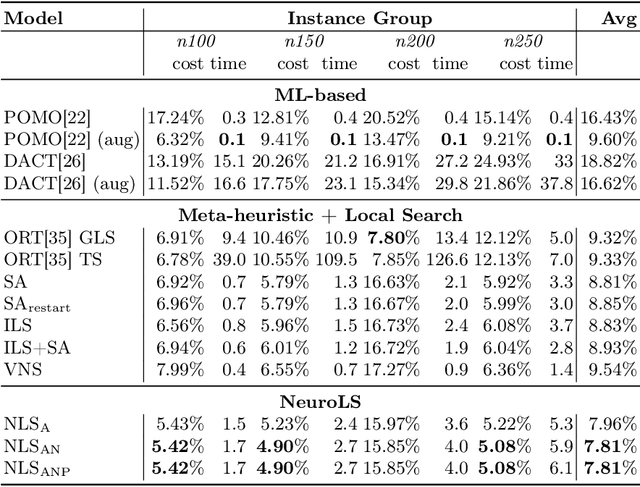
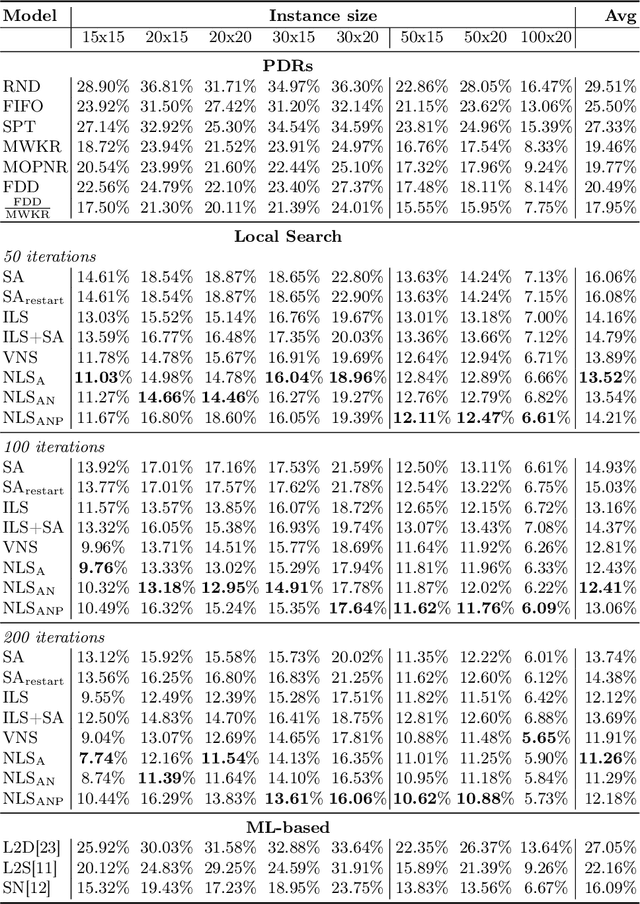
Combinatorial optimization problems are encountered in many practical contexts such as logistics and production, but exact solutions are particularly difficult to find and usually NP-hard for considerable problem sizes. To compute approximate solutions, a zoo of generic as well as problem-specific variants of local search is commonly used. However, which variant to apply to which particular problem is difficult to decide even for experts. In this paper we identify three independent algorithmic aspects of such local search algorithms and formalize their sequential selection over an optimization process as Markov Decision Process (MDP). We design a deep graph neural network as policy model for this MDP, yielding a learned controller for local search called NeuroLS. Ample experimental evidence shows that NeuroLS is able to outperform both, well-known general purpose local search controllers from Operations Research as well as latest machine learning-based approaches.
Large Neighborhood Search based on Neural Construction Heuristics
May 10, 2022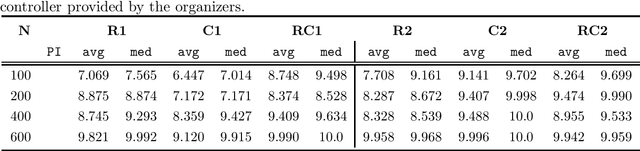
We propose a Large Neighborhood Search (LNS) approach utilizing a learned construction heuristic based on neural networks as repair operator to solve the vehicle routing problem with time windows (VRPTW). Our method uses graph neural networks to encode the problem and auto-regressively decodes a solution and is trained with reinforcement learning on the construction task without requiring any labels for supervision. The neural repair operator is combined with a local search routine, heuristic destruction operators and a selection procedure applied to a small population to arrive at a sophisticated solution approach. The key idea is to use the learned model to re-construct the partially destructed solution and to introduce randomness via the destruction heuristics (or the stochastic policy itself) to effectively explore a large neighborhood.
RP-DQN: An application of Q-Learning to Vehicle Routing Problems
Apr 25, 2021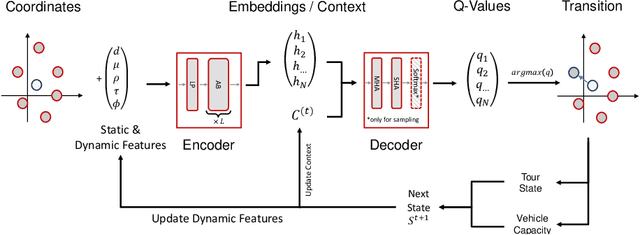
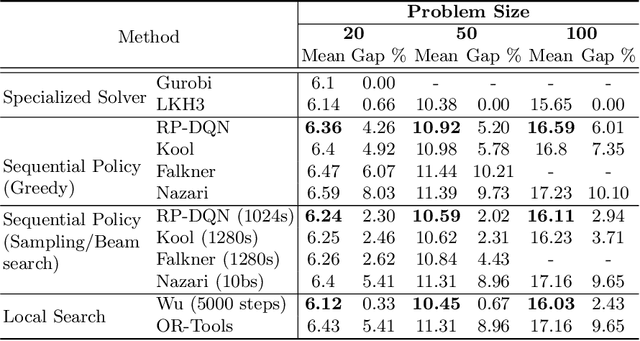
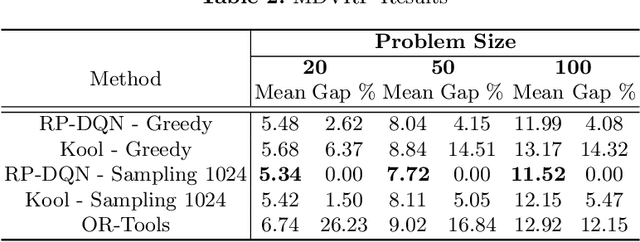
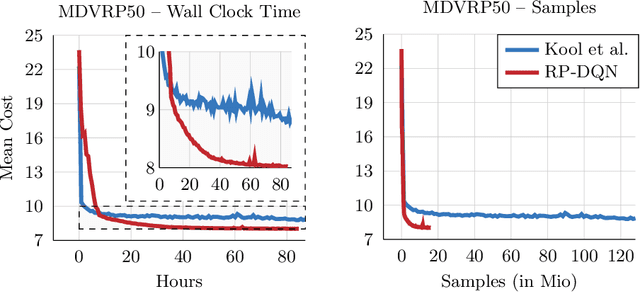
In this paper we present a new approach to tackle complex routing problems with an improved state representation that utilizes the model complexity better than previous methods. We enable this by training from temporal differences. Specifically Q-Learning is employed. We show that our approach achieves state-of-the-art performance for autoregressive policies that sequentially insert nodes to construct solutions on the CVRP. Additionally, we are the first to tackle the MDVRP with machine learning methods and demonstrate that this problem type greatly benefits from our approach over other ML methods.
Learning to Solve Vehicle Routing Problems with Time Windows through Joint Attention
Jun 16, 2020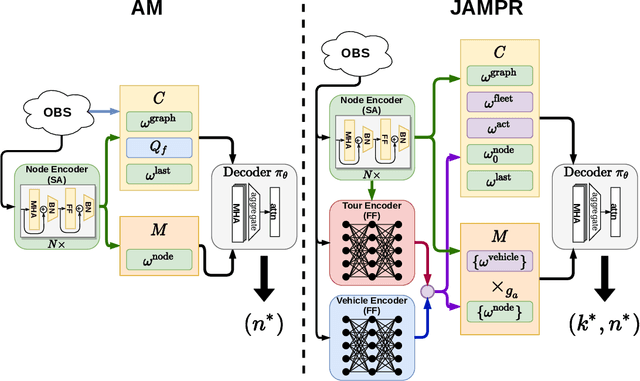
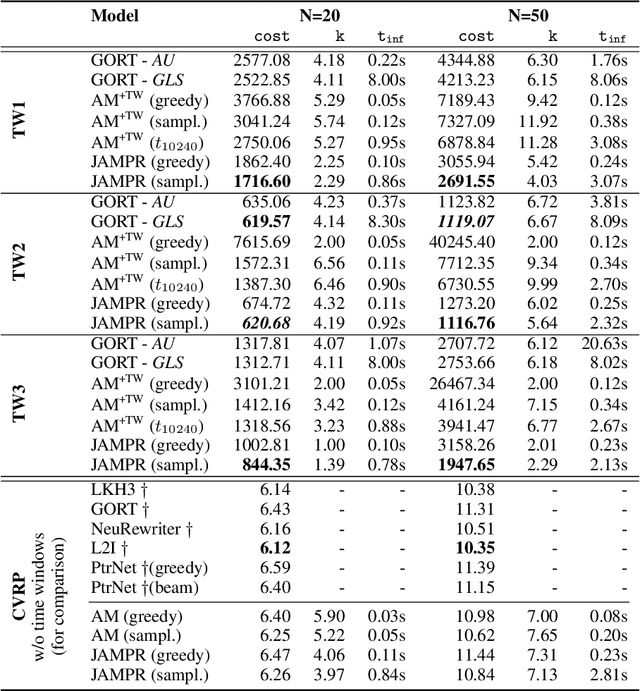
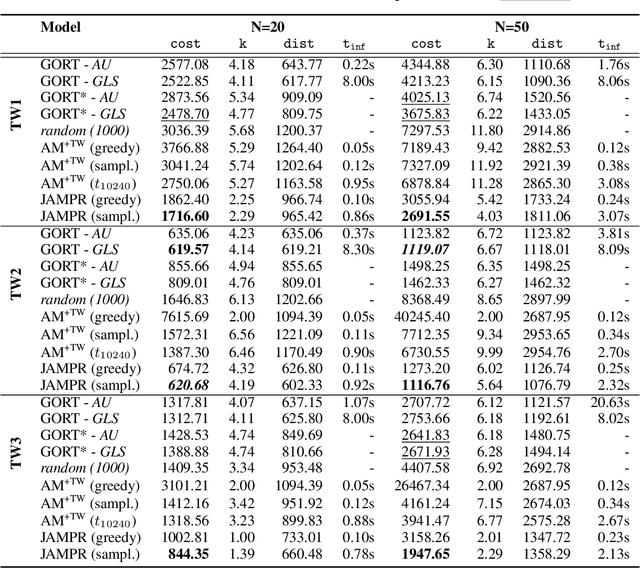
Many real-world vehicle routing problems involve rich sets of constraints with respect to the capacities of the vehicles, time windows for customers etc. While in recent years first machine learning models have been developed to solve basic vehicle routing problems faster than optimization heuristics, complex constraints rarely are taken into consideration. Due to their general procedure to construct solutions sequentially route by route, these methods generalize unfavorably to such problems. In this paper, we develop a policy model that is able to start and extend multiple routes concurrently by using attention on the joint action space of several tours. In that way the model is able to select routes and customers and thus learns to make difficult trade-offs between routes. In comprehensive experiments on three variants of the vehicle routing problem with time windows we show that our model called JAMPR works well for different problem sizes and outperforms the existing state-of-the-art constructive model. For two of the three variants it also creates significantly better solutions than a comparable meta-heuristic solver.