Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRP-DQN: An application of Q-Learning to Vehicle Routing Problems
Apr 25, 2021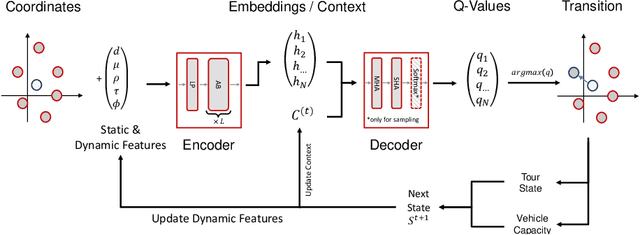
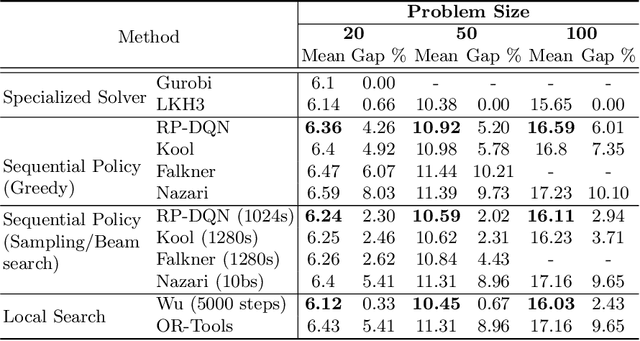
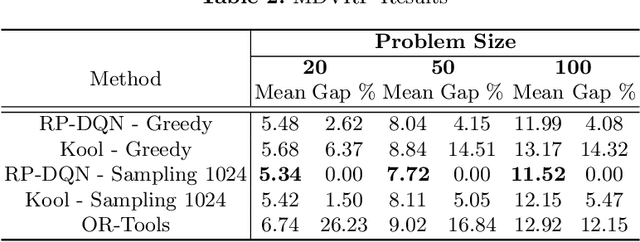
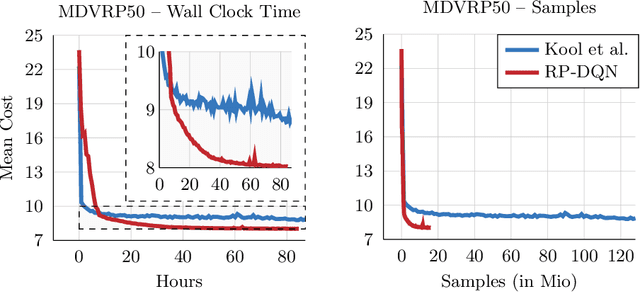
In this paper we present a new approach to tackle complex routing problems with an improved state representation that utilizes the model complexity better than previous methods. We enable this by training from temporal differences. Specifically Q-Learning is employed. We show that our approach achieves state-of-the-art performance for autoregressive policies that sequentially insert nodes to construct solutions on the CVRP. Additionally, we are the first to tackle the MDVRP with machine learning methods and demonstrate that this problem type greatly benefits from our approach over other ML methods.
* 14 pages, 4 figures
Via