 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShelfOcc: Native 3D Supervision beyond LiDAR for Vision-Based Occupancy Estimation
Nov 19, 2025Recent progress in self- and weakly supervised occupancy estimation has largely relied on 2D projection or rendering-based supervision, which suffers from geometric inconsistencies and severe depth bleeding. We thus introduce ShelfOcc, a vision-only method that overcomes these limitations without relying on LiDAR. ShelfOcc brings supervision into native 3D space by generating metrically consistent semantic voxel labels from video, enabling true 3D supervision without any additional sensors or manual 3D annotations. While recent vision-based 3D geometry foundation models provide a promising source of prior knowledge, they do not work out of the box as a prediction due to sparse or noisy and inconsistent geometry, especially in dynamic driving scenes. Our method introduces a dedicated framework that mitigates these issues by filtering and accumulating static geometry consistently across frames, handling dynamic content and propagating semantic information into a stable voxel representation. This data-centric shift in supervision for weakly/shelf-supervised occupancy estimation allows the use of essentially any SOTA occupancy model architecture without relying on LiDAR data. We argue that such high-quality supervision is essential for robust occupancy learning and constitutes an important complementary avenue to architectural innovation. On the Occ3D-nuScenes benchmark, ShelfOcc substantially outperforms all previous weakly/shelf-supervised methods (up to a 34% relative improvement), establishing a new data-driven direction for LiDAR-free 3D scene understanding.
GaussianFlowOcc: Sparse and Weakly Supervised Occupancy Estimation using Gaussian Splatting and Temporal Flow
Feb 25, 2025
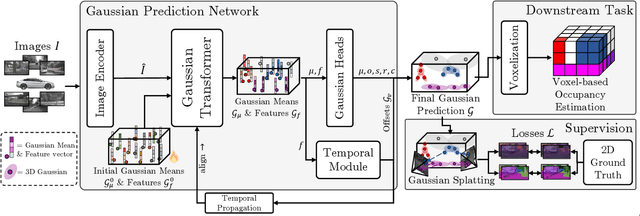
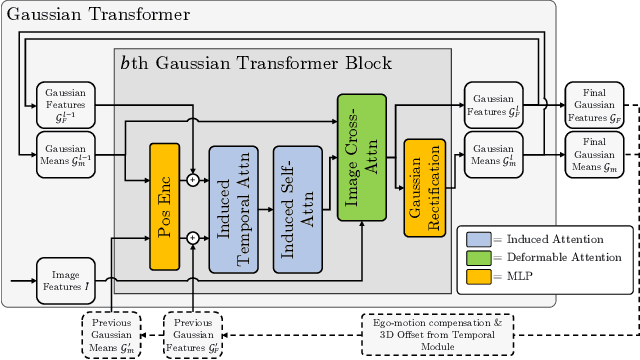

Occupancy estimation has become a prominent task in 3D computer vision, particularly within the autonomous driving community. In this paper, we present a novel approach to occupancy estimation, termed GaussianFlowOcc, which is inspired by Gaussian Splatting and replaces traditional dense voxel grids with a sparse 3D Gaussian representation. Our efficient model architecture based on a Gaussian Transformer significantly reduces computational and memory requirements by eliminating the need for expensive 3D convolutions used with inefficient voxel-based representations that predominantly represent empty 3D spaces. GaussianFlowOcc effectively captures scene dynamics by estimating temporal flow for each Gaussian during the overall network training process, offering a straightforward solution to a complex problem that is often neglected by existing methods. Moreover, GaussianFlowOcc is designed for scalability, as it employs weak supervision and does not require costly dense 3D voxel annotations based on additional data (e.g., LiDAR). Through extensive experimentation, we demonstrate that GaussianFlowOcc significantly outperforms all previous methods for weakly supervised occupancy estimation on the nuScenes dataset while featuring an inference speed that is 50 times faster than current SOTA.
LangOcc: Self-Supervised Open Vocabulary Occupancy Estimation via Volume Rendering
Jul 25, 2024The 3D occupancy estimation task has become an important challenge in the area of vision-based autonomous driving recently. However, most existing camera-based methods rely on costly 3D voxel labels or LiDAR scans for training, limiting their practicality and scalability. Moreover, most methods are tied to a predefined set of classes which they can detect. In this work we present a novel approach for open vocabulary occupancy estimation called LangOcc, that is trained only via camera images, and can detect arbitrary semantics via vision-language alignment. In particular, we distill the knowledge of the strong vision-language aligned encoder CLIP into a 3D occupancy model via differentiable volume rendering. Our model estimates vision-language aligned features in a 3D voxel grid using only images. It is trained in a self-supervised manner by rendering our estimations back to 2D space, where ground-truth features can be computed. This training mechanism automatically supervises the scene geometry, allowing for a straight-forward and powerful training method without any explicit geometry supervision. LangOcc outperforms LiDAR-supervised competitors in open vocabulary occupancy by a large margin, solely relying on vision-based training. We also achieve state-of-the-art results in self-supervised semantic occupancy estimation on the Occ3D-nuScenes dataset, despite not being limited to a specific set of categories, thus demonstrating the effectiveness of our proposed vision-language training.
OccFlowNet: Towards Self-supervised Occupancy Estimation via Differentiable Rendering and Occupancy Flow
Feb 20, 2024



Semantic occupancy has recently gained significant traction as a prominent 3D scene representation. However, most existing methods rely on large and costly datasets with fine-grained 3D voxel labels for training, which limits their practicality and scalability, increasing the need for self-monitored learning in this domain. In this work, we present a novel approach to occupancy estimation inspired by neural radiance field (NeRF) using only 2D labels, which are considerably easier to acquire. In particular, we employ differentiable volumetric rendering to predict depth and semantic maps and train a 3D network based on 2D supervision only. To enhance geometric accuracy and increase the supervisory signal, we introduce temporal rendering of adjacent time steps. Additionally, we introduce occupancy flow as a mechanism to handle dynamic objects in the scene and ensure their temporal consistency. Through extensive experimentation we demonstrate that 2D supervision only is sufficient to achieve state-of-the-art performance compared to methods using 3D labels, while outperforming concurrent 2D approaches. When combining 2D supervision with 3D labels, temporal rendering and occupancy flow we outperform all previous occupancy estimation models significantly. We conclude that the proposed rendering supervision and occupancy flow advances occupancy estimation and further bridges the gap towards self-supervised learning in this domain.
RP-DQN: An application of Q-Learning to Vehicle Routing Problems
Apr 25, 2021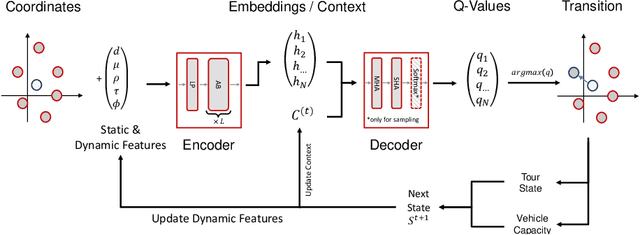
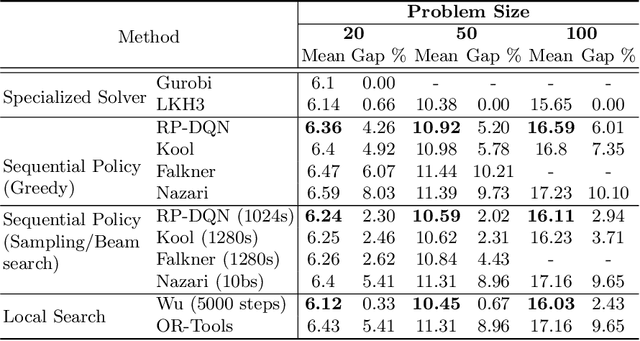
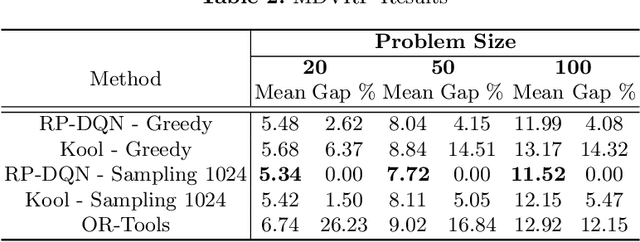
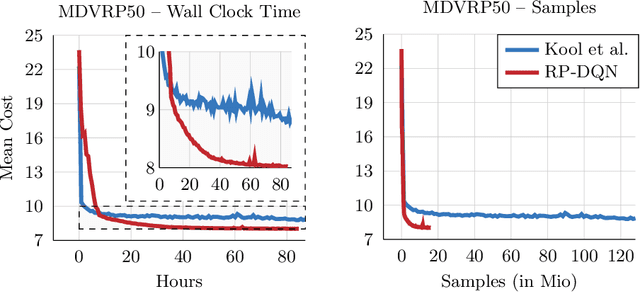
In this paper we present a new approach to tackle complex routing problems with an improved state representation that utilizes the model complexity better than previous methods. We enable this by training from temporal differences. Specifically Q-Learning is employed. We show that our approach achieves state-of-the-art performance for autoregressive policies that sequentially insert nodes to construct solutions on the CVRP. Additionally, we are the first to tackle the MDVRP with machine learning methods and demonstrate that this problem type greatly benefits from our approach over other ML methods.