 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbSAINT: Probabilistic Tabular Regression for Used Car Pricing
Mar 06, 2024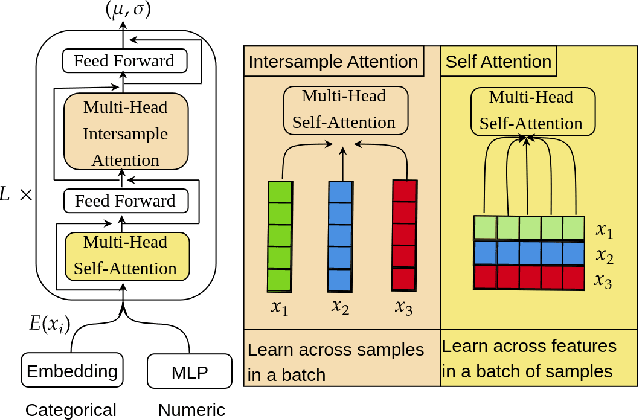
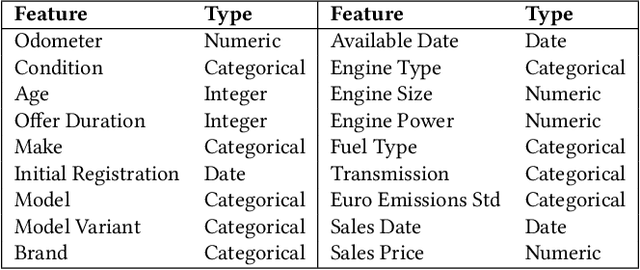
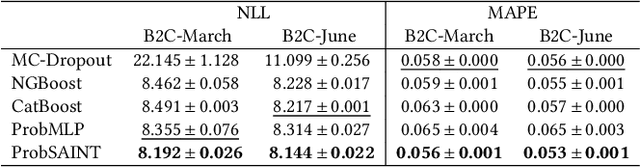
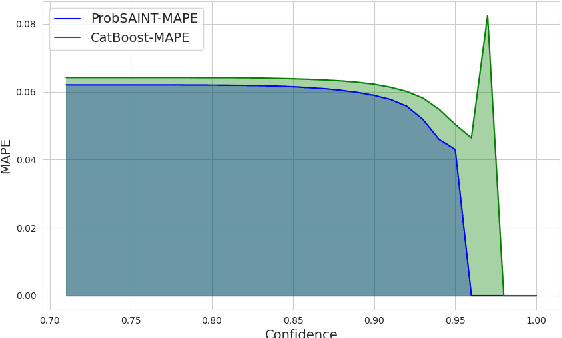
Used car pricing is a critical aspect of the automotive industry, influenced by many economic factors and market dynamics. With the recent surge in online marketplaces and increased demand for used cars, accurate pricing would benefit both buyers and sellers by ensuring fair transactions. However, the transition towards automated pricing algorithms using machine learning necessitates the comprehension of model uncertainties, specifically the ability to flag predictions that the model is unsure about. Although recent literature proposes the use of boosting algorithms or nearest neighbor-based approaches for swift and precise price predictions, encapsulating model uncertainties with such algorithms presents a complex challenge. We introduce ProbSAINT, a model that offers a principled approach for uncertainty quantification of its price predictions, along with accurate point predictions that are comparable to state-of-the-art boosting techniques. Furthermore, acknowledging that the business prefers pricing used cars based on the number of days the vehicle was listed for sale, we show how ProbSAINT can be used as a dynamic forecasting model for predicting price probabilities for different expected offer duration. Our experiments further indicate that ProbSAINT is especially accurate on instances where it is highly certain. This proves the applicability of its probabilistic predictions in real-world scenarios where trustworthiness is crucial.
ClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
Positive-Unlabeled Domain Adaptation
Feb 11, 2022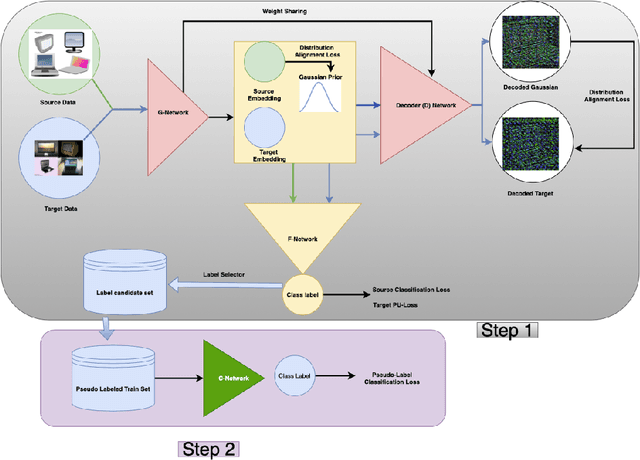
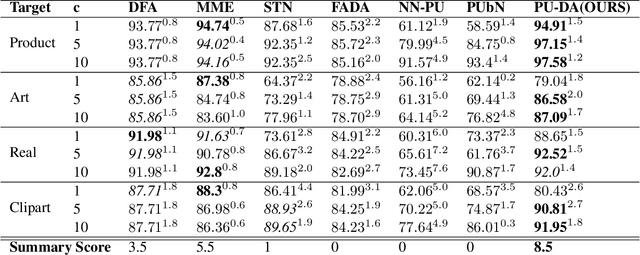


Domain Adaptation methodologies have shown to effectively generalize from a labeled source domain to a label scarce target domain. Previous research has either focused on unlabeled domain adaptation without any target supervision or semi-supervised domain adaptation with few labeled target examples per class. On the other hand Positive-Unlabeled (PU-) Learning has attracted increasing interest in the weakly supervised learning literature since in quite some real world applications positive labels are much easier to obtain than negative ones. In this work we are the first to introduce the challenge of Positive-Unlabeled Domain Adaptation where we aim to generalise from a fully labeled source domain to a target domain where only positive and unlabeled data is available. We present a novel two-step learning approach to this problem by firstly identifying reliable positive and negative pseudo-labels in the target domain guided by source domain labels and a positive-unlabeled risk estimator. This enables us to use a standard classifier on the target domain in a second step. We validate our approach by running experiments on benchmark datasets for visual object recognition. Furthermore we propose real world examples for our setting and validate our superior performance on parking occupancy data.