 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabResFlow: A Normalizing Spline Flow Model for Probabilistic Univariate Tabular Regression
Aug 23, 2025



Tabular regression is a well-studied problem with numerous industrial applications, yet most existing approaches focus on point estimation, often leading to overconfident predictions. This issue is particularly critical in industrial automation, where trustworthy decision-making is essential. Probabilistic regression models address this challenge by modeling prediction uncertainty. However, many conventional methods assume a fixed-shape distribution (typically Gaussian), and resort to estimating distribution parameters. This assumption is often restrictive, as real-world target distributions can be highly complex. To overcome this limitation, we introduce TabResFlow, a Normalizing Spline Flow model designed specifically for univariate tabular regression, where commonly used simple flow networks like RealNVP and Masked Autoregressive Flow (MAF) are unsuitable. TabResFlow consists of three key components: (1) An MLP encoder for each numerical feature. (2) A fully connected ResNet backbone for expressive feature extraction. (3) A conditional spline-based normalizing flow for flexible and tractable density estimation. We evaluate TabResFlow on nine public benchmark datasets, demonstrating that it consistently surpasses existing probabilistic regression models on likelihood scores. Our results demonstrate 9.64% improvement compared to the strongest probabilistic regression model (TreeFlow), and on average 5.6 times speed-up in inference time compared to the strongest deep learning alternative (NodeFlow). Additionally, we validate the practical applicability of TabResFlow in a real-world used car price prediction task under selective regression. To measure performance in this setting, we introduce a novel Area Under Risk Coverage (AURC) metric and show that TabResFlow achieves superior results across this metric.
Positive-Unlabeled Domain Adaptation
Feb 11, 2022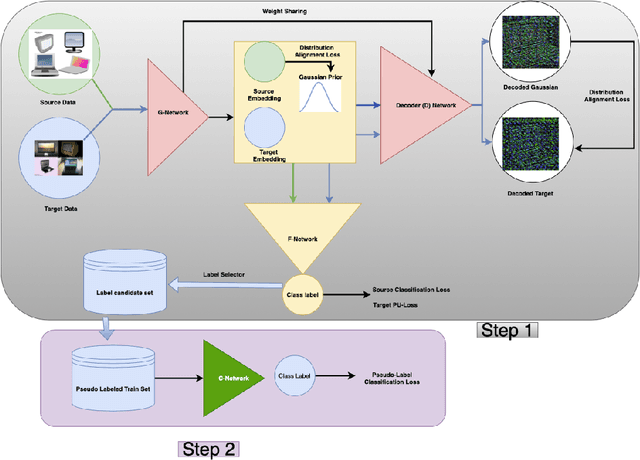
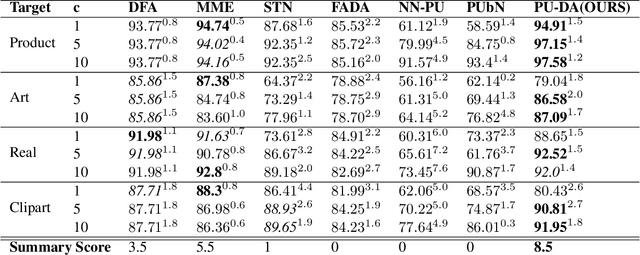


Domain Adaptation methodologies have shown to effectively generalize from a labeled source domain to a label scarce target domain. Previous research has either focused on unlabeled domain adaptation without any target supervision or semi-supervised domain adaptation with few labeled target examples per class. On the other hand Positive-Unlabeled (PU-) Learning has attracted increasing interest in the weakly supervised learning literature since in quite some real world applications positive labels are much easier to obtain than negative ones. In this work we are the first to introduce the challenge of Positive-Unlabeled Domain Adaptation where we aim to generalise from a fully labeled source domain to a target domain where only positive and unlabeled data is available. We present a novel two-step learning approach to this problem by firstly identifying reliable positive and negative pseudo-labels in the target domain guided by source domain labels and a positive-unlabeled risk estimator. This enables us to use a standard classifier on the target domain in a second step. We validate our approach by running experiments on benchmark datasets for visual object recognition. Furthermore we propose real world examples for our setting and validate our superior performance on parking occupancy data.