 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Dimension for Large-Scale Geometric Learning
Oct 11, 2022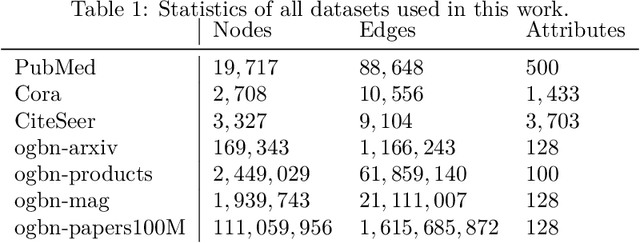

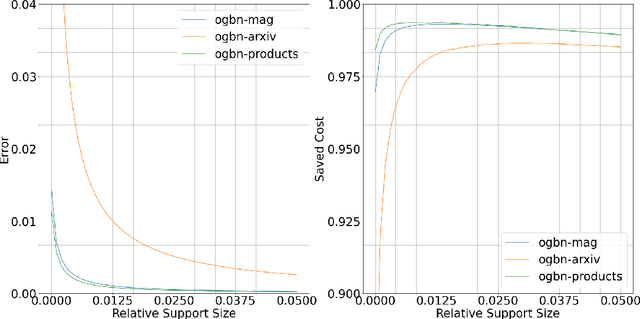
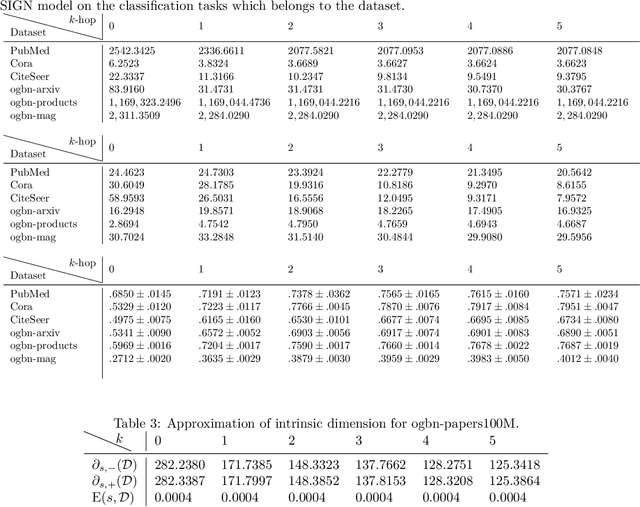
The concept of dimension is essential to grasp the complexity of data. A naive approach to determine the dimension of a dataset is based on the number of attributes. More sophisticated methods derive a notion of intrinsic dimension (ID) that employs more complex feature functions, e.g., distances between data points. Yet, many of these approaches are based on empirical observations, cannot cope with the geometric character of contemporary datasets, and do lack an axiomatic foundation. A different approach was proposed by V. Pestov, who links the intrinsic dimension axiomatically to the mathematical concentration of measure phenomenon. First methods to compute this and related notions for ID were computationally intractable for large-scale real-world datasets. In the present work, we derive a computationally feasible method for determining said axiomatic ID functions. Moreover, we demonstrate how the geometric properties of complex data are accounted for in our modeling. In particular, we propose a principle way to incorporate neighborhood information, as in graph data, into the ID. This allows for new insights into common graph learning procedures, which we illustrate by experiments on the Open Graph Benchmark.
Intrinsic dimension and its application to association rules
May 15, 2018
The curse of dimensionality in the realm of association rules is twofold. Firstly, we have the well known exponential increase in computational complexity with increasing item set size. Secondly, there is a \emph{related curse} concerned with the distribution of (spare) data itself in high dimension. The former problem is often coped with by projection, i.e., feature selection, whereas the best known strategy for the latter is avoidance. This work summarizes the first attempt to provide a computationally feasible method for measuring the extent of dimension curse present in a data set with respect to a particular class machine of learning procedures. This recent development enables the application of various other methods from geometric analysis to be investigated and applied in machine learning procedures in the presence of high dimension.
Intrinsic dimension of concept lattices
Jan 24, 2018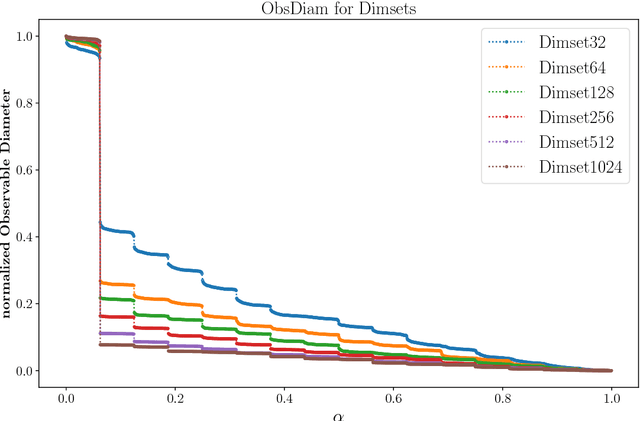
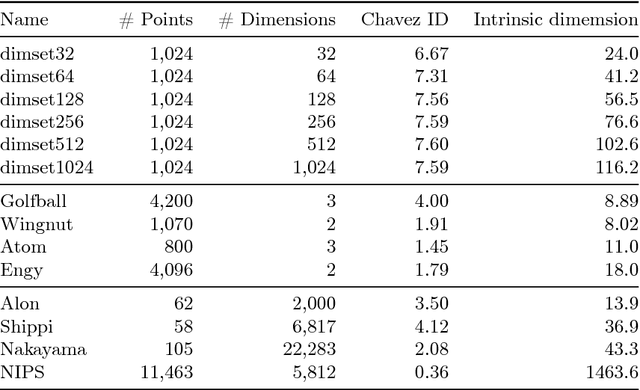


Geometric analysis is a very capable theory to understand the influence of the high dimensionality of the input data in machine learning (ML) and knowledge discovery (KD). With our approach we can assess how far the application of a specific KD/ML-algorithm to a concrete data set is prone to the curse of dimensionality. To this end we extend V.~Pestov's axiomatic approach to the instrinsic dimension of data sets, based on the seminal work by M.~Gromov on concentration phenomena, and provide an adaptable and computationally feasible model for studying observable geometric invariants associated to features that are natural to both the data and the learning procedure. In detail, we investigate data represented by formal contexts and give first theoretical as well as experimental insights into the intrinsic dimension of a concept lattice. Because of the correspondence between formal concepts and maximal cliques in graphs, applications to social network analysis are at hand.