 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBotVerse: Real-Time Event-Driven Simulation of Social Agents
Mar 31, 2026BotVerse is a scalable, event-driven framework for high-fidelity social simulation using LLM-based agents. It addresses the ethical risks of studying autonomous agents on live networks by isolating interactions within a controlled environment while grounding them in real-time content streams from the Bluesky ecosystem. The system features an asynchronous orchestration API and a simulation engine that emulates human-like temporal patterns and cognitive memory. Through the Synthetic Social Observatory, researchers can deploy customizable personas and observe multimodal interactions at scale. We demonstrate BotVersevia a coordinated disinformation scenario, providing a safe, experimental framework for red-teaming and computational social scientists. A video demonstration of the framework is available at https://youtu.be/eZSzO5Jarqk.
From Online Behaviours to Images: A Novel Approach to Social Bot Detection
Apr 15, 2023



Online Social Networks have revolutionized how we consume and share information, but they have also led to a proliferation of content not always reliable and accurate. One particular type of social accounts is known to promote unreputable content, hyperpartisan, and propagandistic information. They are automated accounts, commonly called bots. Focusing on Twitter accounts, we propose a novel approach to bot detection: we first propose a new algorithm that transforms the sequence of actions that an account performs into an image; then, we leverage the strength of Convolutional Neural Networks to proceed with image classification. We compare our performances with state-of-the-art results for bot detection on genuine accounts / bot accounts datasets well known in the literature. The results confirm the effectiveness of the proposal, because the detection capability is on par with the state of the art, if not better in some cases.
Demystifying Misconceptions in Social Bots Research
Mar 30, 2023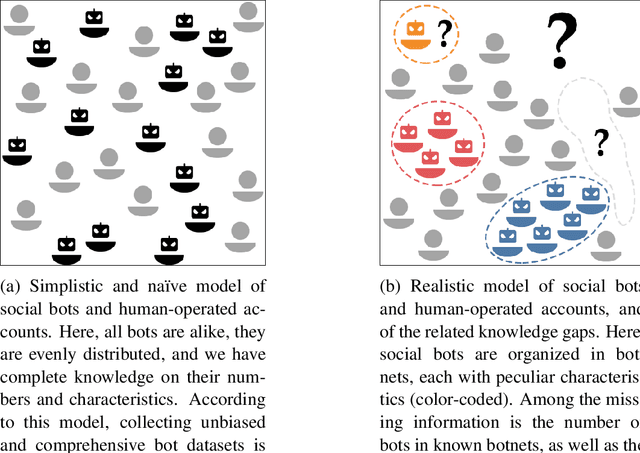
The science of social bots seeks knowledge and solutions to one of the most debated forms of online misinformation. Yet, social bots research is plagued by widespread biases, hyped results, and misconceptions that set the stage for ambiguities, unrealistic expectations, and seemingly irreconcilable findings. Overcoming such issues is instrumental towards ensuring reliable solutions and reaffirming the validity of the scientific method. In this contribution we revise some recent results in social bots research, highlighting and correcting factual errors as well as methodological and conceptual issues. More importantly, we demystify common misconceptions, addressing fundamental points on how social bots research is discussed. Our analysis surfaces the need to discuss misinformation research in a rigorous, unbiased, and responsible way. This article bolsters such effort by identifying and refuting common fallacious arguments used by both proponents and opponents of social bots research as well as providing indications on the correct methodologies and sound directions for future research in the field.
Adversarial machine learning for protecting against online manipulation
Nov 23, 2021

Adversarial examples are inputs to a machine learning system that result in an incorrect output from that system. Attacks launched through this type of input can cause severe consequences: for example, in the field of image recognition, a stop signal can be misclassified as a speed limit indication.However, adversarial examples also represent the fuel for a flurry of research directions in different domains and applications. Here, we give an overview of how they can be profitably exploited as powerful tools to build stronger learning models, capable of better-withstanding attacks, for two crucial tasks: fake news and social bot detection.
A study on text-score disagreement in online reviews
Jul 21, 2017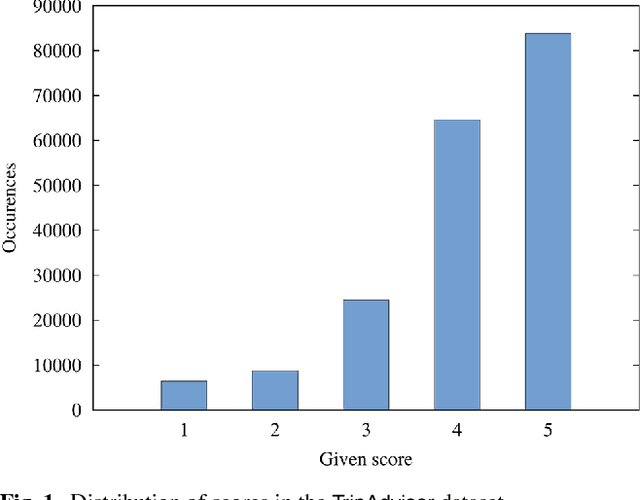


In this paper, we focus on online reviews and employ artificial intelligence tools, taken from the cognitive computing field, to help understanding the relationships between the textual part of the review and the assigned numerical score. We move from the intuitions that 1) a set of textual reviews expressing different sentiments may feature the same score (and vice-versa); and 2) detecting and analyzing the mismatches between the review content and the actual score may benefit both service providers and consumers, by highlighting specific factors of satisfaction (and dissatisfaction) in texts. To prove the intuitions, we adopt sentiment analysis techniques and we concentrate on hotel reviews, to find polarity mismatches therein. In particular, we first train a text classifier with a set of annotated hotel reviews, taken from the Booking website. Then, we analyze a large dataset, with around 160k hotel reviews collected from Tripadvisor, with the aim of detecting a polarity mismatch, indicating if the textual content of the review is in line, or not, with the associated score. Using well established artificial intelligence techniques and analyzing in depth the reviews featuring a mismatch between the text polarity and the score, we find that -on a scale of five stars- those reviews ranked with middle scores include a mixture of positive and negative aspects. The approach proposed here, beside acting as a polarity detector, provides an effective selection of reviews -on an initial very large dataset- that may allow both consumers and providers to focus directly on the review subset featuring a text/score disagreement, which conveniently convey to the user a summary of positive and negative features of the review target.
Social Fingerprinting: detection of spambot groups through DNA-inspired behavioral modeling
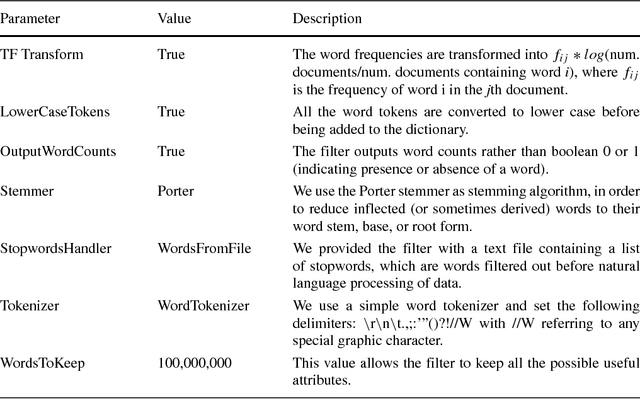
Mar 13, 2017



Spambot detection in online social networks is a long-lasting challenge involving the study and design of detection techniques capable of efficiently identifying ever-evolving spammers. Recently, a new wave of social spambots has emerged, with advanced human-like characteristics that allow them to go undetected even by current state-of-the-art algorithms. In this paper, we show that efficient spambots detection can be achieved via an in-depth analysis of their collective behaviors exploiting the digital DNA technique for modeling the behaviors of social network users. Inspired by its biological counterpart, in the digital DNA representation the behavioral lifetime of a digital account is encoded in a sequence of characters. Then, we define a similarity measure for such digital DNA sequences. We build upon digital DNA and the similarity between groups of users to characterize both genuine accounts and spambots. Leveraging such characterization, we design the Social Fingerprinting technique, which is able to discriminate among spambots and genuine accounts in both a supervised and an unsupervised fashion. We finally evaluate the effectiveness of Social Fingerprinting and we compare it with three state-of-the-art detection algorithms. Among the peculiarities of our approach is the possibility to apply off-the-shelf DNA analysis techniques to study online users behaviors and to efficiently rely on a limited number of lightweight account characteristics.
A matter of words: NLP for quality evaluation of Wikipedia medical articles
Mar 07, 2016
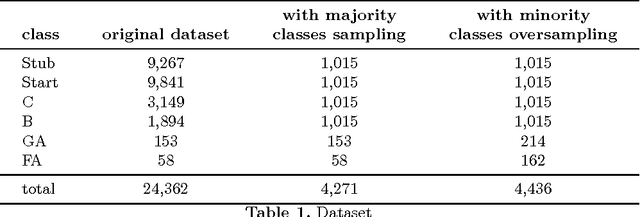

Automatic quality evaluation of Web information is a task with many fields of applications and of great relevance, especially in critical domains like the medical one. We move from the intuition that the quality of content of medical Web documents is affected by features related with the specific domain. First, the usage of a specific vocabulary (Domain Informativeness); then, the adoption of specific codes (like those used in the infoboxes of Wikipedia articles) and the type of document (e.g., historical and technical ones). In this paper, we propose to leverage specific domain features to improve the results of the evaluation of Wikipedia medical articles. In particular, we evaluate the articles adopting an "actionable" model, whose features are related to the content of the articles, so that the model can also directly suggest strategies for improving a given article quality. We rely on Natural Language Processing (NLP) and dictionaries-based techniques in order to extract the bio-medical concepts in a text. We prove the effectiveness of our approach by classifying the medical articles of the Wikipedia Medicine Portal, which have been previously manually labeled by the Wiki Project team. The results of our experiments confirm that, by considering domain-oriented features, it is possible to obtain sensible improvements with respect to existing solutions, mainly for those articles that other approaches have less correctly classified. Other than being interesting by their own, the results call for further research in the area of domain specific features suitable for Web data quality assessment.
DNA-inspired online behavioral modeling and its application to spambot detection
Jan 30, 2016
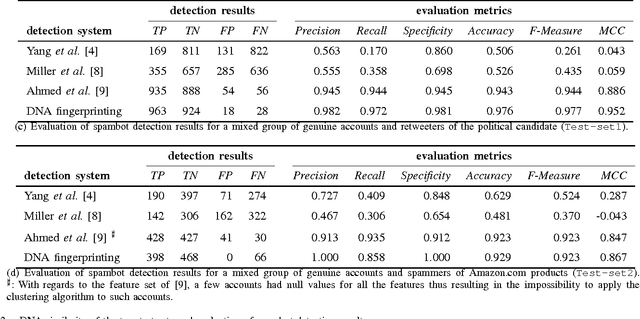
We propose a strikingly novel, simple, and effective approach to model online user behavior: we extract and analyze digital DNA sequences from user online actions and we use Twitter as a benchmark to test our proposal. We obtain an incisive and compact DNA-inspired characterization of user actions. Then, we apply standard DNA analysis techniques to discriminate between genuine and spambot accounts on Twitter. An experimental campaign supports our proposal, showing its effectiveness and viability. To the best of our knowledge, we are the first ones to identify and adapt DNA-inspired techniques to online user behavioral modeling. While Twitter spambot detection is a specific use case on a specific social media, our proposed methodology is platform and technology agnostic, hence paving the way for diverse behavioral characterization tasks.
Fame for sale: efficient detection of fake Twitter followers
Nov 10, 2015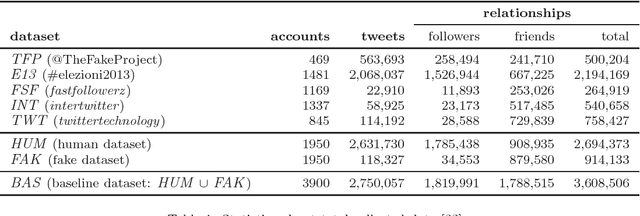

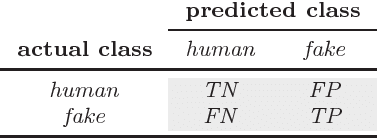

$\textit{Fake followers}$ are those Twitter accounts specifically created to inflate the number of followers of a target account. Fake followers are dangerous for the social platform and beyond, since they may alter concepts like popularity and influence in the Twittersphere - hence impacting on economy, politics, and society. In this paper, we contribute along different dimensions. First, we review some of the most relevant existing features and rules (proposed by Academia and Media) for anomalous Twitter accounts detection. Second, we create a baseline dataset of verified human and fake follower accounts. Such baseline dataset is publicly available to the scientific community. Then, we exploit the baseline dataset to train a set of machine-learning classifiers built over the reviewed rules and features. Our results show that most of the rules proposed by Media provide unsatisfactory performance in revealing fake followers, while features proposed in the past by Academia for spam detection provide good results. Building on the most promising features, we revise the classifiers both in terms of reduction of overfitting and cost for gathering the data needed to compute the features. The final result is a novel $\textit{Class A}$ classifier, general enough to thwart overfitting, lightweight thanks to the usage of the less costly features, and still able to correctly classify more than 95% of the accounts of the original training set. We ultimately perform an information fusion-based sensitivity analysis, to assess the global sensitivity of each of the features employed by the classifier. The findings reported in this paper, other than being supported by a thorough experimental methodology and interesting on their own, also pave the way for further investigation on the novel issue of fake Twitter followers.
Hacking Smart Machines with Smarter Ones: How to Extract Meaningful Data from Machine Learning Classifiers
Jun 19, 2013
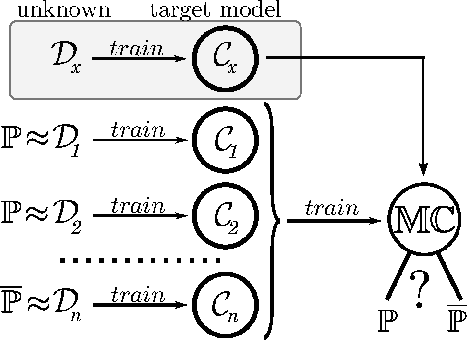

Machine Learning (ML) algorithms are used to train computers to perform a variety of complex tasks and improve with experience. Computers learn how to recognize patterns, make unintended decisions, or react to a dynamic environment. Certain trained machines may be more effective than others because they are based on more suitable ML algorithms or because they were trained through superior training sets. Although ML algorithms are known and publicly released, training sets may not be reasonably ascertainable and, indeed, may be guarded as trade secrets. While much research has been performed about the privacy of the elements of training sets, in this paper we focus our attention on ML classifiers and on the statistical information that can be unconsciously or maliciously revealed from them. We show that it is possible to infer unexpected but useful information from ML classifiers. In particular, we build a novel meta-classifier and train it to hack other classifiers, obtaining meaningful information about their training sets. This kind of information leakage can be exploited, for example, by a vendor to build more effective classifiers or to simply acquire trade secrets from a competitor's apparatus, potentially violating its intellectual property rights.