 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAP-MOT: Unsupervised Graph-based Position Weighted Person Multi-camera Multi-object Tracking in a Highly Congested Space
Oct 24, 2025GRAP-MOT is a new approach for solving the person MOT problem dedicated to videos of closed areas with overlapping multi-camera views, where person occlusion frequently occurs. Our novel graph-weighted solution updates a person's identification label online based on tracks and the person's characteristic features. To find the best solution, we deeply investigated all elements of the MOT process, including feature extraction, tracking, and community search. Furthermore, GRAP-MOT is equipped with a person's position estimation module, which gives additional key information to the MOT method, ensuring better results than methods without position data. We tested GRAP-MOT on recordings acquired in a closed-area model and on publicly available real datasets that fulfil the requirement of a highly congested space, showing the superiority of our proposition. Finally, we analyzed existing metrics used to compare MOT algorithms and concluded that IDF1 is more adequate than MOTA in such comparisons. We made our code, along with the acquired dataset, publicly available.
Development of a Realistic Crowd Simulation Environment for Fine-grained Validation of People Tracking Methods
Apr 26, 2023



Generally, crowd datasets can be collected or generated from real or synthetic sources. Real data is generated by using infrastructure-based sensors (such as static cameras or other sensors). The use of simulation tools can significantly reduce the time required to generate scenario-specific crowd datasets, facilitate data-driven research, and next build functional machine learning models. The main goal of this work was to develop an extension of crowd simulation (named CrowdSim2) and prove its usability in the application of people-tracking algorithms. The simulator is developed using the very popular Unity 3D engine with particular emphasis on the aspects of realism in the environment, weather conditions, traffic, and the movement and models of individual agents. Finally, three methods of tracking were used to validate generated dataset: IOU-Tracker, Deep-Sort, and Deep-TAMA.
CrowdSim2: an Open Synthetic Benchmark for Object Detectors
Apr 11, 2023Data scarcity has become one of the main obstacles to developing supervised models based on Artificial Intelligence in Computer Vision. Indeed, Deep Learning-based models systematically struggle when applied in new scenarios never seen during training and may not be adequately tested in non-ordinary yet crucial real-world situations. This paper presents and publicly releases CrowdSim2, a new synthetic collection of images suitable for people and vehicle detection gathered from a simulator based on the Unity graphical engine. It consists of thousands of images gathered from various synthetic scenarios resembling the real world, where we varied some factors of interest, such as the weather conditions and the number of objects in the scenes. The labels are automatically collected and consist of bounding boxes that precisely localize objects belonging to the two object classes, leaving out humans from the annotation pipeline. We exploited this new benchmark as a testing ground for some state-of-the-art detectors, showing that our simulated scenarios can be a valuable tool for measuring their performances in a controlled environment.
Classification supporting COVID-19 diagnostics based on patient survey data
Nov 24, 2020
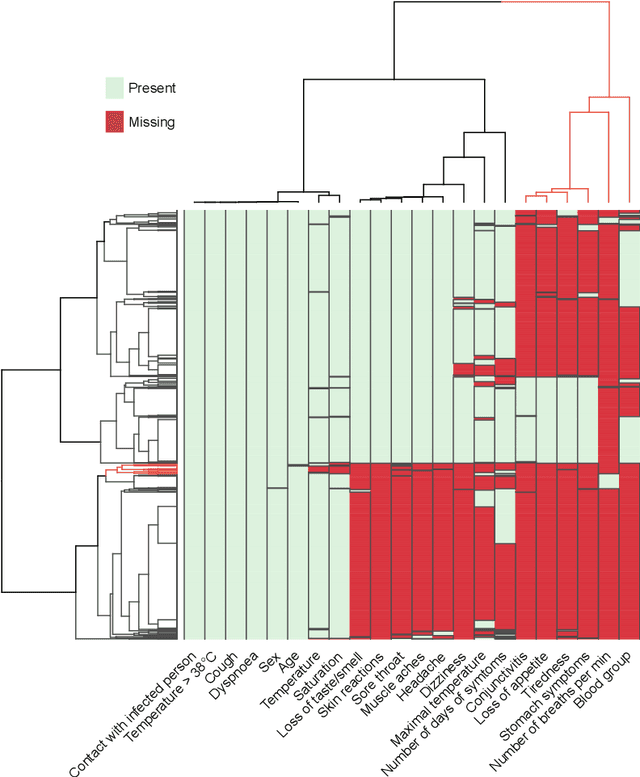

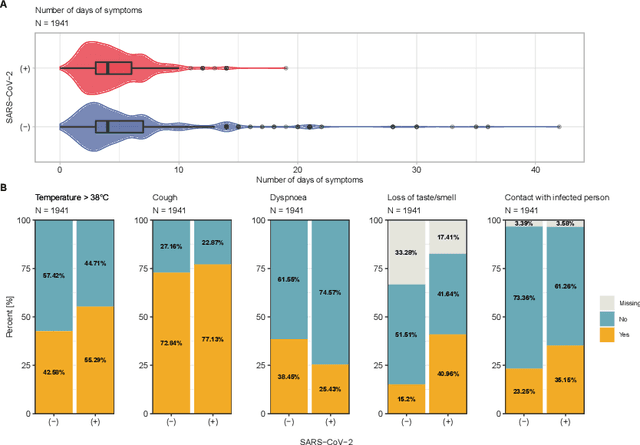
Distinguishing COVID-19 from other flu-like illnesses can be difficult due to ambiguous symptoms and still an initial experience of doctors. Whereas, it is crucial to filter out those sick patients who do not need to be tested for SARS-CoV-2 infection, especially in the event of the overwhelming increase in disease. As a part of the presented research, logistic regression and XGBoost classifiers, that allow for effective screening of patients for COVID-19, were generated. Each of the methods was tuned to achieve an assumed acceptable threshold of negative predictive values during classification. Additionally, an explanation of the obtained classification models was presented. The explanation enables the users to understand what was the basis of the decision made by the model. The obtained classification models provided the basis for the DECODE service (decode.polsl.pl), which can serve as support in screening patients with COVID-19 disease. Moreover, the data set constituting the basis for the analyses performed is made available to the research community. This data set consisting of more than 3,000 examples is based on questionnaires collected at a hospital in Poland.