 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOBDrone: a Drone Video Dataset for Man OverBoard Rescue
Mar 15, 2022



Modern Unmanned Aerial Vehicles (UAV) equipped with cameras can play an essential role in speeding up the identification and rescue of people who have fallen overboard, i.e., man overboard (MOB). To this end, Artificial Intelligence techniques can be leveraged for the automatic understanding of visual data acquired from drones. However, detecting people at sea in aerial imagery is challenging primarily due to the lack of specialized annotated datasets for training and testing detectors for this task. To fill this gap, we introduce and publicly release the MOBDrone benchmark, a collection of more than 125K drone-view images in a marine environment under several conditions, such as different altitudes, camera shooting angles, and illumination. We manually annotated more than 180K objects, of which about 113K man overboard, precisely localizing them with bounding boxes. Moreover, we conduct a thorough performance analysis of several state-of-the-art object detectors on the MOBDrone data, serving as baselines for further research.
MAFER: a Multi-resolution Approach to Facial Expression Recognition
May 06, 2021



Emotions play a central role in the social life of every human being, and their study, which represents a multidisciplinary subject, embraces a great variety of research fields. Especially concerning the latter, the analysis of facial expressions represents a very active research area due to its relevance to human-computer interaction applications. In such a context, Facial Expression Recognition (FER) is the task of recognizing expressions on human faces. Typically, face images are acquired by cameras that have, by nature, different characteristics, such as the output resolution. It has been already shown in the literature that Deep Learning models applied to face recognition experience a degradation in their performance when tested against multi-resolution scenarios. Since the FER task involves analyzing face images that can be acquired with heterogeneous sources, thus involving images with different quality, it is plausible to expect that resolution plays an important role in such a case too. Stemming from such a hypothesis, we prove the benefits of multi-resolution training for models tasked with recognizing facial expressions. Hence, we propose a two-step learning procedure, named MAFER, to train DCNNs to empower them to generate robust predictions across a wide range of resolutions. A relevant feature of MAFER is that it is task-agnostic, i.e., it can be used complementarily to other objective-related techniques. To assess the effectiveness of the proposed approach, we performed an extensive experimental campaign on publicly available datasets: \fer{}, \raf{}, and \oulu{}. For a multi-resolution context, we observe that with our approach, learning models improve upon the current SotA while reporting comparable results in fix-resolution contexts. Finally, we analyze the performance of our models and observe the higher discrimination power of deep features generated from them.
A Multi-resolution Approach to Expression Recognition in the Wild
Mar 09, 2021
Facial expressions play a fundamental role in human communication. Indeed, they typically reveal the real emotional status of people beyond the spoken language. Moreover, the comprehension of human affect based on visual patterns is a key ingredient for any human-machine interaction system and, for such reasons, the task of Facial Expression Recognition (FER) draws both scientific and industrial interest. In the recent years, Deep Learning techniques reached very high performance on FER by exploiting different architectures and learning paradigms. In such a context, we propose a multi-resolution approach to solve the FER task. We ground our intuition on the observation that often faces images are acquired at different resolutions. Thus, directly considering such property while training a model can help achieve higher performance on recognizing facial expressions. To our aim, we use a ResNet-like architecture, equipped with Squeeze-and-Excitation blocks, trained on the Affect-in-the-Wild 2 dataset. Not being available a test set, we conduct tests and models selection by employing the validation set only on which we achieve more than 90\% accuracy on classifying the seven expressions that the dataset comprises.
Expression Recognition Analysis in the Wild
Jan 22, 2021

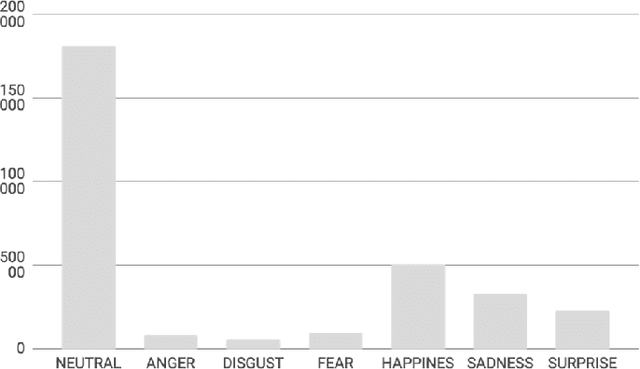

Facial Expression Recognition(FER) is one of the most important topic in Human-Computer interactions(HCI). In this work we report details and experimental results about a facial expression recognition method based on state-of-the-art methods. We fine-tuned a SeNet deep learning architecture pre-trained on the well-known VGGFace2 dataset, on the AffWild2 facial expression recognition dataset. The main goal of this work is to define a baseline for a novel method we are going to propose in the near future. This paper is also required by the Affective Behavior Analysis in-the-wild (ABAW) competition in order to evaluate on the test set this approach. The results reported here are on the validation set and are related on the Expression Challenge part (seven basic emotion recognition) of the competition. We will update them as soon as the actual results on the test set will be published on the leaderboard.