 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Weight for Text Classification
Mar 28, 2019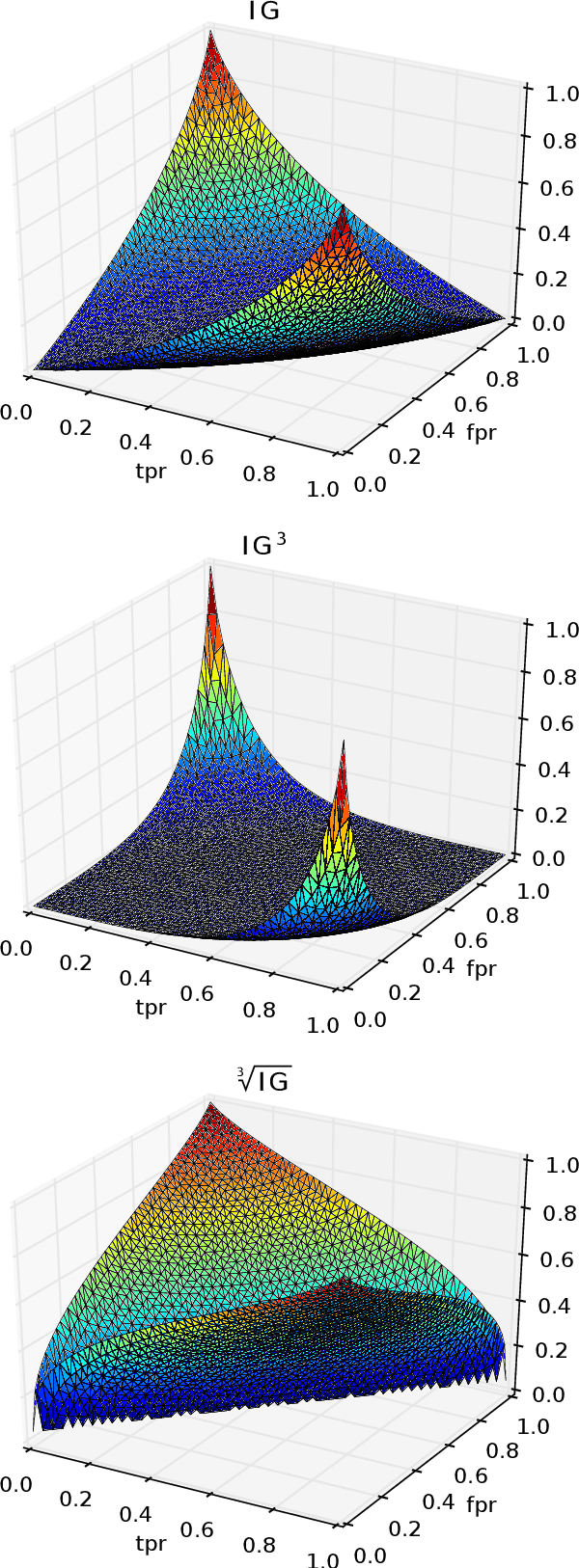
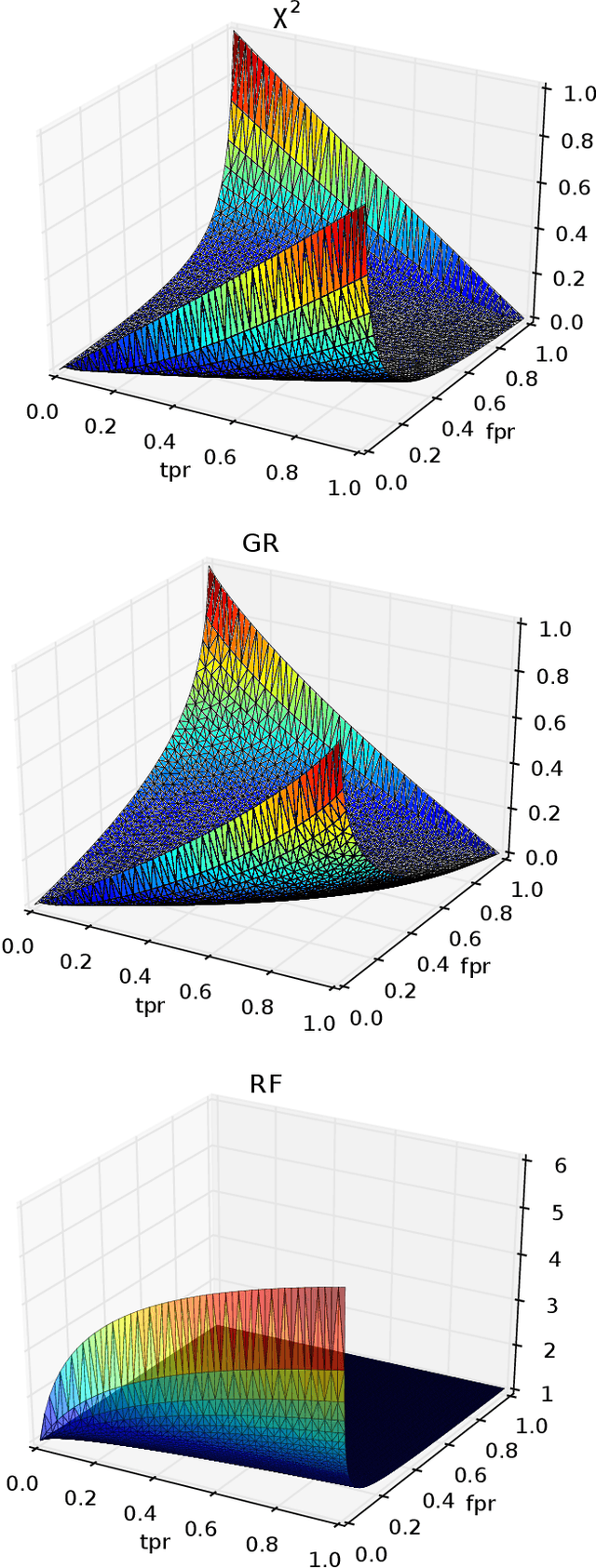
In information retrieval (IR) and related tasks, term weighting approaches typically consider the frequency of the term in the document and in the collection in order to compute a score reflecting the importance of the term for the document. In tasks characterized by the presence of training data (such as text classification) it seems logical that the term weighting function should take into account the distribution (as estimated from training data) of the term across the classes of interest. Although `supervised term weighting' approaches that use this intuition have been described before, they have failed to show consistent improvements. In this article we analyse the possible reasons for this failure, and call consolidated assumptions into question. Following this criticism we propose a novel supervised term weighting approach that, instead of relying on any predefined formula, learns a term weighting function optimised on the training set of interest; we dub this approach \emph{Learning to Weight} (LTW). The experiments that we run on several well-known benchmarks, and using different learning methods, show that our method outperforms previous term weighting approaches in text classification.
A Recurrent Neural Network for Sentiment Quantification
Sep 04, 2018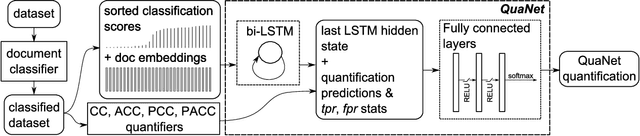
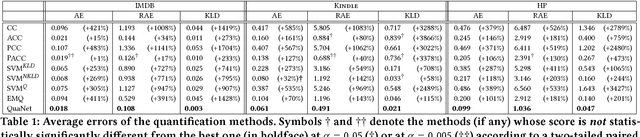
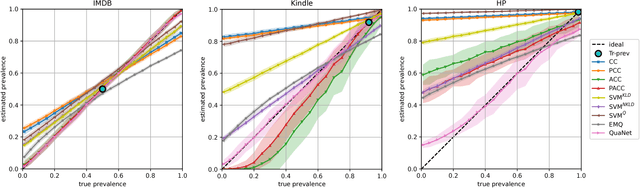
Quantification is a supervised learning task that consists in predicting, given a set of classes C and a set D of unlabelled items, the prevalence (or relative frequency) p(c|D) of each class c in C. Quantification can in principle be solved by classifying all the unlabelled items and counting how many of them have been attributed to each class. However, this "classify and count" approach has been shown to yield suboptimal quantification accuracy; this has established quantification as a task of its own, and given rise to a number of methods specifically devised for it. We propose a recurrent neural network architecture for quantification (that we call QuaNet) that observes the classification predictions to learn higher-order "quantification embeddings", which are then refined by incorporating quantification predictions of simple classify-and-count-like methods. We test {QuaNet on sentiment quantification on text, showing that it substantially outperforms several state-of-the-art baselines.
Exploring epoch-dependent stochastic residual networks
Apr 20, 2017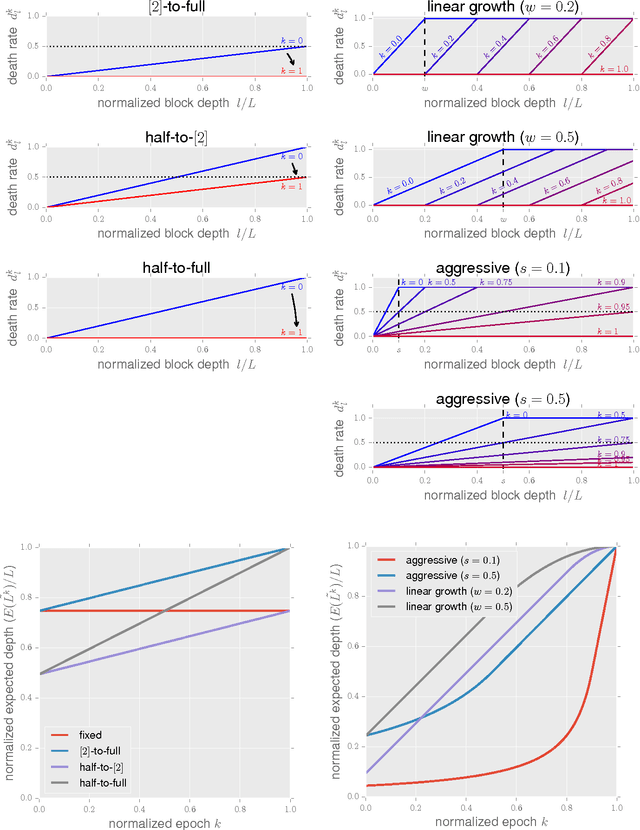
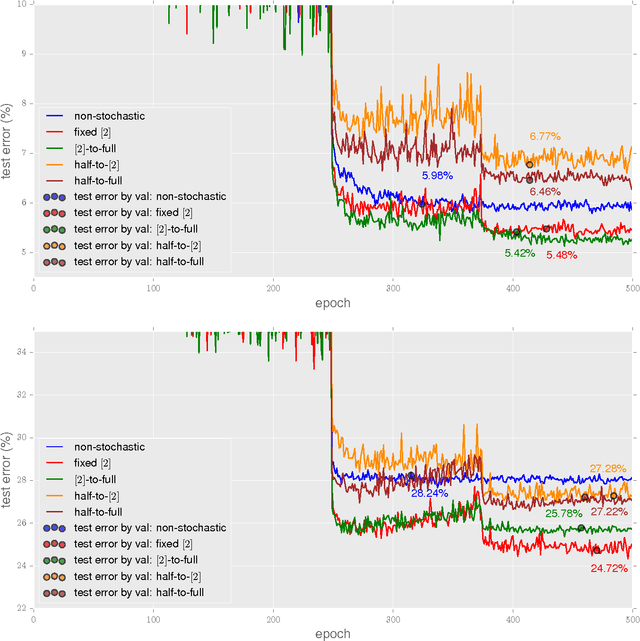
The recently proposed stochastic residual networks selectively activate or bypass the layers during training, based on independent stochastic choices, each of which following a probability distribution that is fixed in advance. In this paper we present a first exploration on the use of an epoch-dependent distribution, starting with a higher probability of bypassing deeper layers and then activating them more frequently as training progresses. Preliminary results are mixed, yet they show some potential of adding an epoch-dependent management of distributions, worth of further investigation.
Picture It In Your Mind: Generating High Level Visual Representations From Textual Descriptions
Jun 23, 2016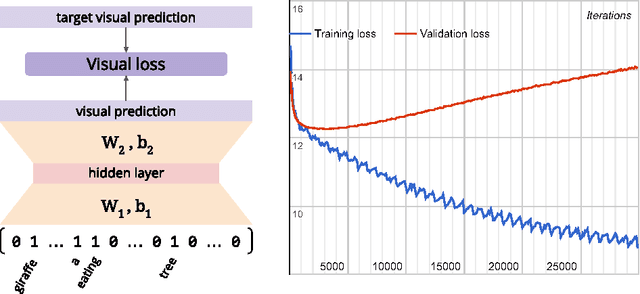
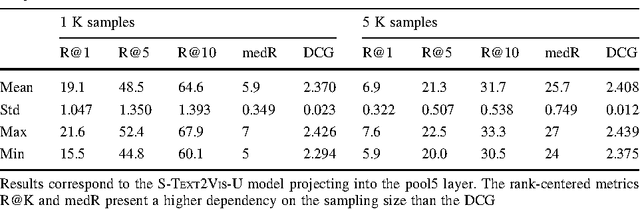
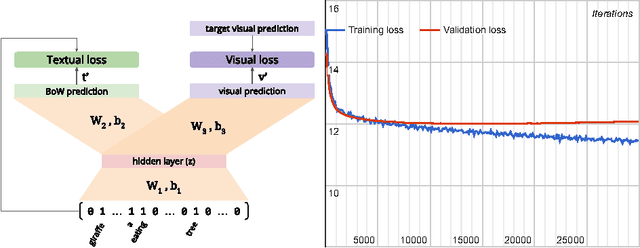
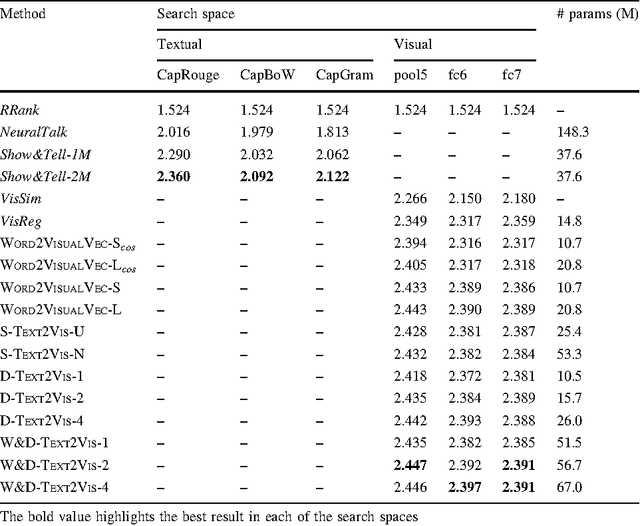
In this paper we tackle the problem of image search when the query is a short textual description of the image the user is looking for. We choose to implement the actual search process as a similarity search in a visual feature space, by learning to translate a textual query into a visual representation. Searching in the visual feature space has the advantage that any update to the translation model does not require to reprocess the, typically huge, image collection on which the search is performed. We propose Text2Vis, a neural network that generates a visual representation, in the visual feature space of the fc6-fc7 layers of ImageNet, from a short descriptive text. Text2Vis optimizes two loss functions, using a stochastic loss-selection method. A visual-focused loss is aimed at learning the actual text-to-visual feature mapping, while a text-focused loss is aimed at modeling the higher-level semantic concepts expressed in language and countering the overfit on non-relevant visual components of the visual loss. We report preliminary results on the MS-COCO dataset.