 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssisting the Human Fact-Checkers: Detecting All Previously Fact-Checked Claims in a Document
Paper and Code
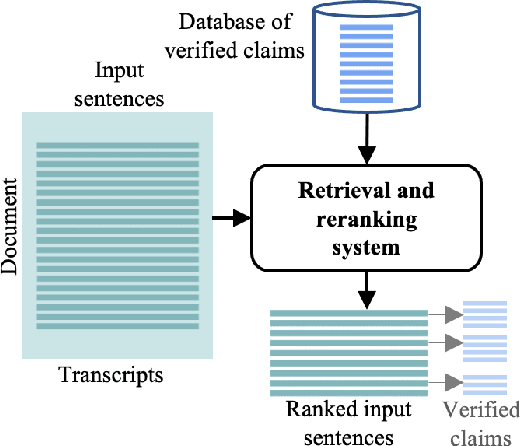
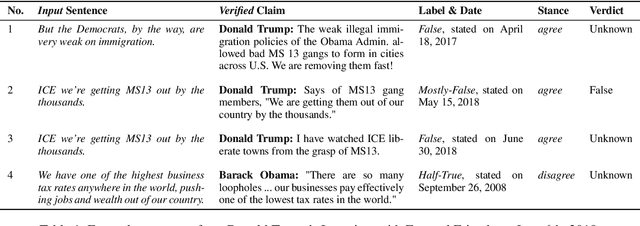

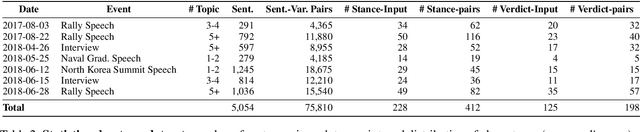
Given the recent proliferation of false claims online, there has been a lot of manual fact-checking effort. As this is very time-consuming, human fact-checkers can benefit from tools that can support them and make them more efficient. Here, we focus on building a system that could provide such support. Given an input document, it aims to detect all sentences that contain a claim that can be verified by some previously fact-checked claims (from a given database). The output is a re-ranked list of the document sentences, so that those that can be verified are ranked as high as possible, together with corresponding evidence. Unlike previous work, which has looked into claim retrieval, here we take a document-level perspective. We create a new manually annotated dataset for the task, and we propose suitable evaluation measures. We further experiment with a learning-to-rank approach, achieving sizable performance gains over several strong baselines. Our analysis demonstrates the importance of modeling text similarity and stance, while also taking into account the veracity of the retrieved previously fact-checked claims. We believe that this research would be of interest to fact-checkers, journalists, media, and regulatory authorities.