 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the NLP4IF-2021 Shared Tasks on Fighting the COVID-19 Infodemic and Censorship Detection
Paper and Code
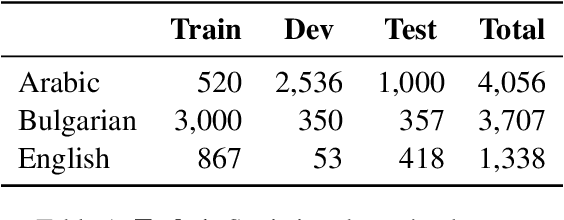
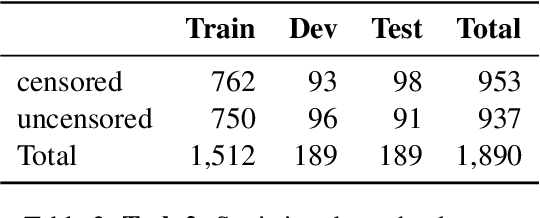
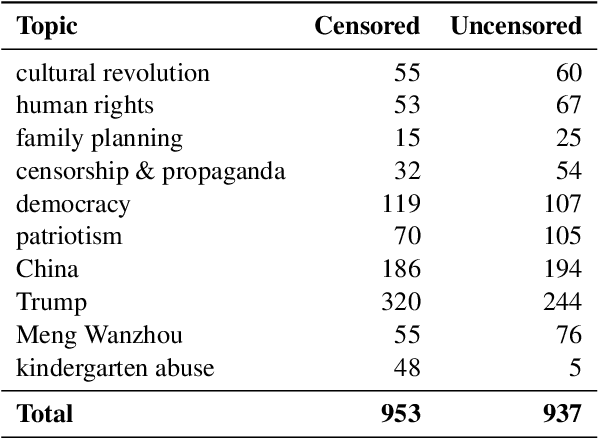
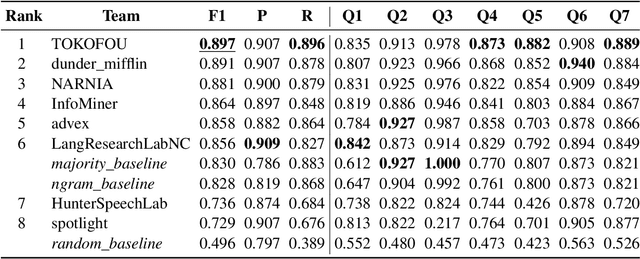
We present the results and the main findings of the NLP4IF-2021 shared tasks. Task 1 focused on fighting the COVID-19 infodemic in social media, and it was offered in Arabic, Bulgarian, and English. Given a tweet, it asked to predict whether that tweet contains a verifiable claim, and if so, whether it is likely to be false, is of general interest, is likely to be harmful, and is worthy of manual fact-checking; also, whether it is harmful to society, and whether it requires the attention of policy makers. Task~2 focused on censorship detection, and was offered in Chinese. A total of ten teams submitted systems for task 1, and one team participated in task 2; nine teams also submitted a system description paper. Here, we present the tasks, analyze the results, and discuss the system submissions and the methods they used. Most submissions achieved sizable improvements over several baselines, and the best systems used pre-trained Transformers and ensembles. The data, the scorers and the leaderboards for the tasks are available at http://gitlab.com/NLP4IF/nlp4if-2021.