 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting Fire with Fire: Adversarial Prompting to Generate a Misinformation Detection Dataset
Jan 09, 2024The recent success in language generation capabilities of large language models (LLMs), such as GPT, Bard, Llama etc., can potentially lead to concerns about their possible misuse in inducing mass agitation and communal hatred via generating fake news and spreading misinformation. Traditional means of developing a misinformation ground-truth dataset does not scale well because of the extensive manual effort required to annotate the data. In this paper, we propose an LLM-based approach of creating silver-standard ground-truth datasets for identifying misinformation. Specifically speaking, given a trusted news article, our proposed approach involves prompting LLMs to automatically generate a summarised version of the original article. The prompts in our proposed approach act as a controlling mechanism to generate specific types of factual incorrectness in the generated summaries, e.g., incorrect quantities, false attributions etc. To investigate the usefulness of this dataset, we conduct a set of experiments where we train a range of supervised models for the task of misinformation detection.
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021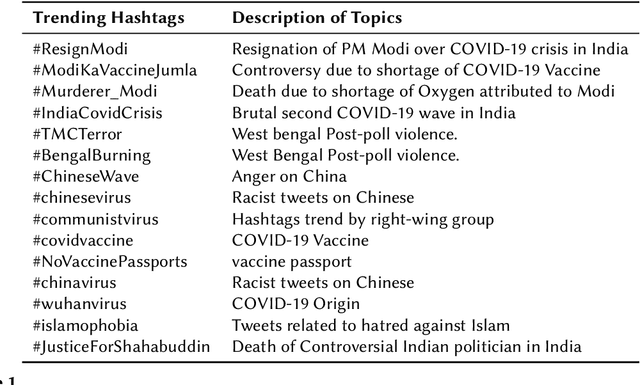
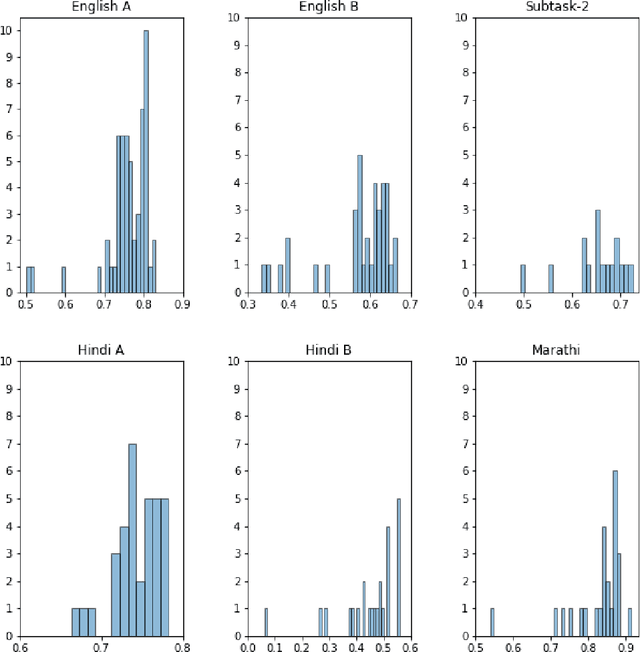
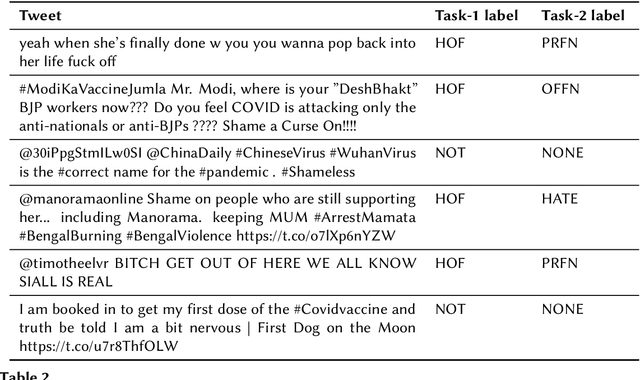
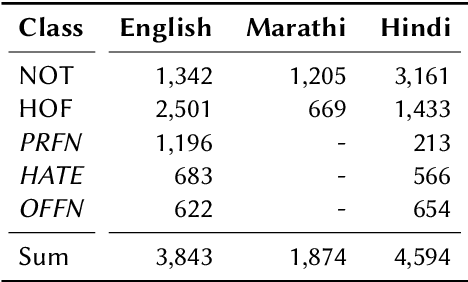
The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.
Overview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages
Aug 12, 2021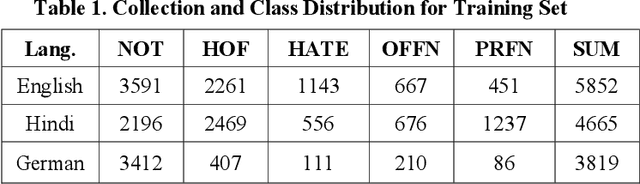
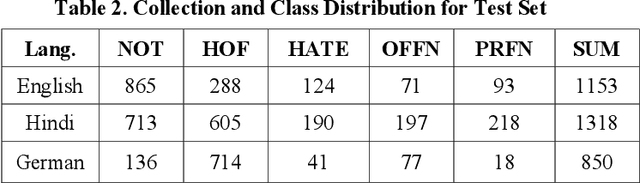
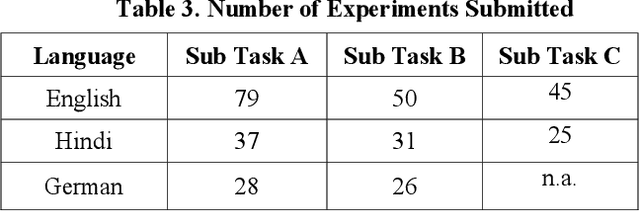
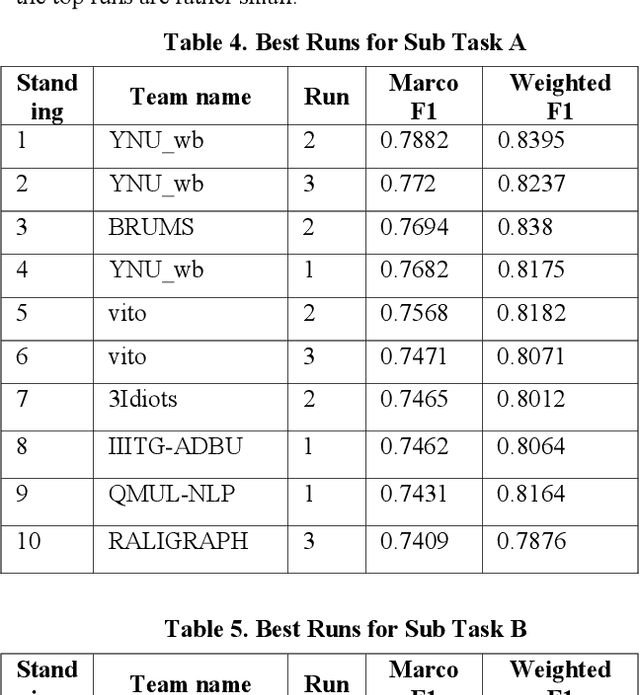
With the growth of social media, the spread of hate speech is also increasing rapidly. Social media are widely used in many countries. Also Hate Speech is spreading in these countries. This brings a need for multilingual Hate Speech detection algorithms. Much research in this area is dedicated to English at the moment. The HASOC track intends to provide a platform to develop and optimize Hate Speech detection algorithms for Hindi, German and English. The dataset is collected from a Twitter archive and pre-classified by a machine learning system. HASOC has two sub-task for all three languages: task A is a binary classification problem (Hate and Not Offensive) while task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY. Overall, 252 runs were submitted by 40 teams. The performance of the best classification algorithms for task A are F1 measures of 0.51, 0.53 and 0.52 for English, Hindi, and German, respectively. For task B, the best classification algorithms achieved F1 measures of 0.26, 0.33 and 0.29 for English, Hindi, and German, respectively. This article presents the tasks and the data development as well as the results. The best performing algorithms were mainly variants of the transformer architecture BERT. However, also other systems were applied with good success
An Empirical Evaluation of Text Representation Schemes on Multilingual Social Web to Filter the Textual Aggression
Apr 16, 2019
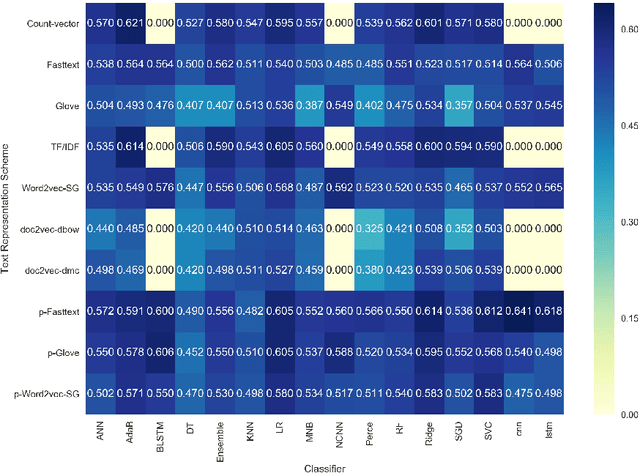

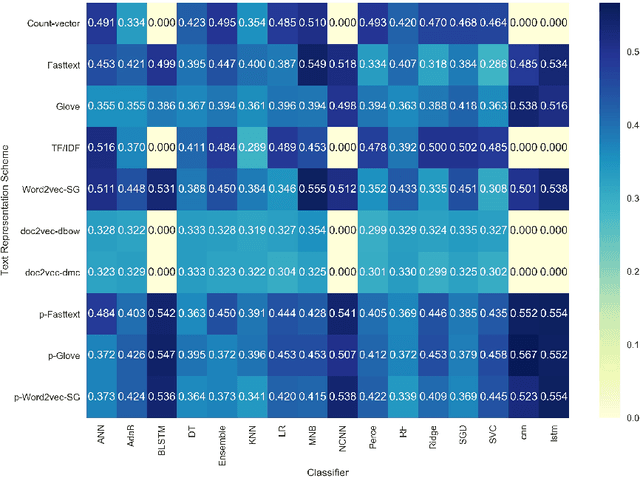
This paper attempt to study the effectiveness of text representation schemes on two tasks namely: User Aggression and Fact Detection from the social media contents. In User Aggression detection, The aim is to identify the level of aggression from the contents generated in the Social media and written in the English, Devanagari Hindi and Romanized Hindi. Aggression levels are categorized into three predefined classes namely: `Non-aggressive`, `Overtly Aggressive`, and `Covertly Aggressive`. During the disaster-related incident, Social media like, Twitter is flooded with millions of posts. In such emergency situations, identification of factual posts is important for organizations involved in the relief operation. We anticipated this problem as a combination of classification and Ranking problem. This paper presents a comparison of various text representation scheme based on BoW techniques, distributed word/sentence representation, transfer learning on classifiers. Weighted $F_1$ score is used as a primary evaluation metric. Results show that text representation using BoW performs better than word embedding on machine learning classifiers. While pre-trained Word embedding techniques perform better on classifiers based on deep neural net. Recent transfer learning model like ELMO, ULMFiT are fine-tuned for the Aggression classification task. However, results are not at par with pre-trained word embedding model. Overall, word embedding using fastText produce best weighted $F_1$-score than Word2Vec and Glove. Results are further improved using pre-trained vector model. Statistical significance tests are employed to ensure the significance of the classification results. In the case of lexically different test Dataset, other than training Dataset, deep neural models are more robust and perform substantially better than machine learning classifiers.