 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages
Aug 12, 2021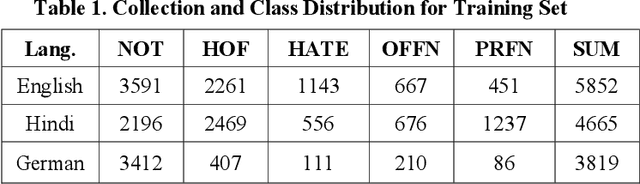
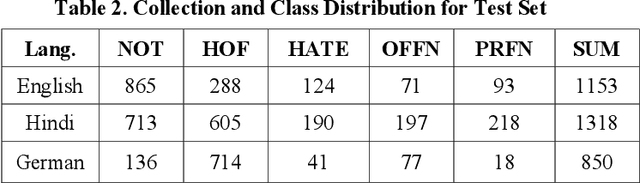
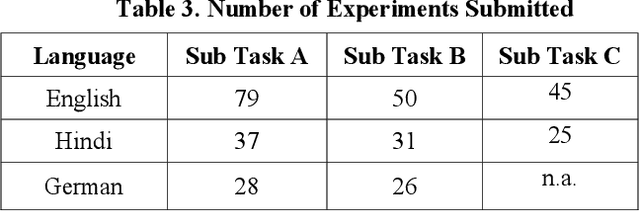
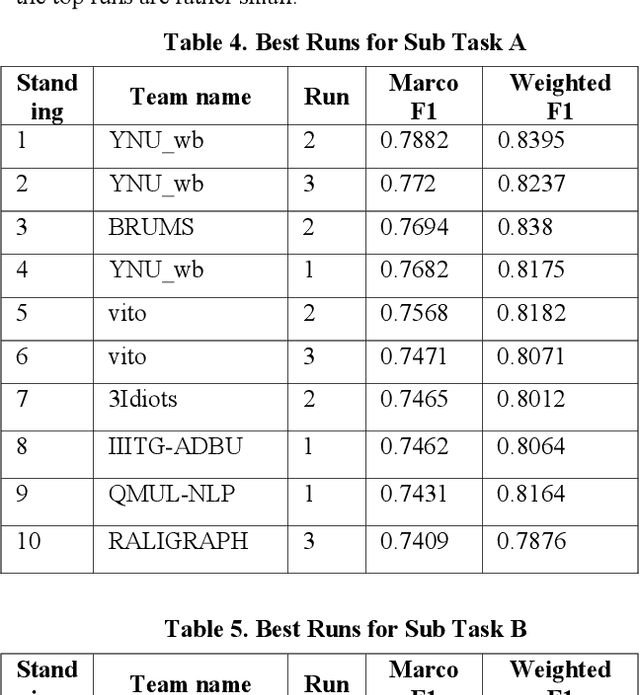
With the growth of social media, the spread of hate speech is also increasing rapidly. Social media are widely used in many countries. Also Hate Speech is spreading in these countries. This brings a need for multilingual Hate Speech detection algorithms. Much research in this area is dedicated to English at the moment. The HASOC track intends to provide a platform to develop and optimize Hate Speech detection algorithms for Hindi, German and English. The dataset is collected from a Twitter archive and pre-classified by a machine learning system. HASOC has two sub-task for all three languages: task A is a binary classification problem (Hate and Not Offensive) while task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY. Overall, 252 runs were submitted by 40 teams. The performance of the best classification algorithms for task A are F1 measures of 0.51, 0.53 and 0.52 for English, Hindi, and German, respectively. For task B, the best classification algorithms achieved F1 measures of 0.26, 0.33 and 0.29 for English, Hindi, and German, respectively. This article presents the tasks and the data development as well as the results. The best performing algorithms were mainly variants of the transformer architecture BERT. However, also other systems were applied with good success