 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Deep Learning based Model for Erythrocytes Classification and Quantification in Sickle Cell Disease
May 02, 2023The shape of erythrocytes or red blood cells is altered in several pathological conditions. Therefore, identifying and quantifying different erythrocyte shapes can help diagnose various diseases and assist in designing a treatment strategy. Machine Learning (ML) can be efficiently used to identify and quantify distorted erythrocyte morphologies. In this paper, we proposed a customized deep convolutional neural network (CNN) model to classify and quantify the distorted and normal morphology of erythrocytes from the images taken from the blood samples of patients suffering from Sickle cell disease ( SCD). We chose SCD as a model disease condition due to the presence of diverse erythrocyte morphologies in the blood samples of SCD patients. For the analysis, we used 428 raw microscopic images of SCD blood samples and generated the dataset consisting of 10, 377 single-cell images. We focused on three well-defined erythrocyte shapes, including discocytes, oval, and sickle. We used 18 layered deep CNN architecture to identify and quantify these shapes with 81% accuracy, outperforming other models. We also used SHAP and LIME for further interpretability. The proposed model can be helpful for the quick and accurate analysis of SCD blood samples by the clinicians and help them make the right decision for better management of SCD.
Word frequency and sentiment analysis of twitter messages during Coronavirus pandemic
Apr 08, 2020
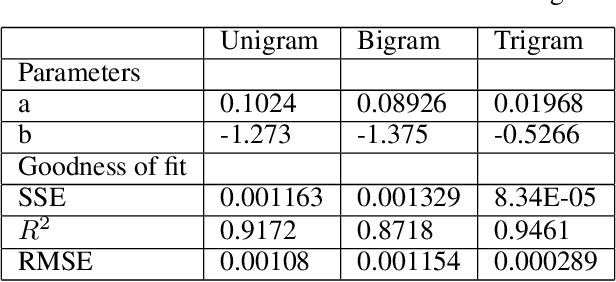


The Coronavirus pandemic has taken the world by storm as also the social media. As the awareness about the ailment increased, so did messages, videos and posts acknowledging its presence. The social networking site, Twitter, demonstrated similar effect with the number of posts related to coronavirus showing an unprecedented growth in a very short span of time. This paper presents a statistical analysis of the twitter messages related to this disease posted since January 2020. Two types of empirical studies have been performed. The first is on word frequency and the second on sentiments of the individual tweet messages. Inspection of the word frequency is useful in characterizing the patterns or trends in the words used on the site. This would also reflect on the psychology of the twitter users at this critical juncture. Unigram, bigram and trigram frequencies have been modeled by power law distribution. The results have been validated by Sum of Square Error (SSE), R2 and Root Mean Square Error (RMSE). High values of R2 and low values of SSE and RMSE lay the grounds for the goodness of fit of this model. Sentiment analysis has been conducted to understand the general attitudes of the twitter users at this time. Both tweets by general public and WHO were part of the corpus. The results showed that the majority of the tweets had a positive polarity and only about 15% were negative.