 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiCQA : A Lightweight Complex Question Answering System
Feb 25, 2026Over the last twenty years, significant progress has been made in designing and implementing Question Answering (QA) systems. However, addressing complex questions, the answers to which are spread across multiple documents, remains a challenging problem. Recent QA systems that are designed to handle complex questions work either on the basis of knowledge graphs, or utilise contem- porary neural models that are expensive to train, in terms of both computational resources and the volume of training data required. In this paper, we present LiCQA, an unsupervised question answer- ing model that works primarily on the basis of corpus evidence. We empirically compare the effectiveness and efficiency of LiCQA with two recently presented QA systems, which are based on different underlying principles. The results of our experiments show that LiCQA significantly outperforms these two state-of-the-art systems on benchmark data with noteworthy reduction in latency.
Fine Grained Evaluation of LLMs-as-Judges
Jan 13, 2026A good deal of recent research has focused on how Large Language Models (LLMs) may be used as `judges' in place of humans to evaluate the quality of the output produced by various text / image processing systems. Within this broader context, a number of studies have investigated the specific question of how effectively LLMs can be used as relevance assessors for the standard ad hoc task in Information Retrieval (IR). We extend these studies by looking at additional questions. Most importantly, we use a Wikipedia based test collection created by the INEX initiative, and prompt LLMs to not only judge whether documents are relevant / non-relevant, but to highlight relevant passages in documents that it regards as useful. The human relevance assessors involved in creating this collection were given analogous instructions, i.e., they were asked to highlight all passages within a document that respond to the information need expressed in a query. This enables us to evaluate the quality of LLMs as judges not only at the document level, but to also quantify how often these `judges' are right for the right reasons. Our findings suggest that LLMs-as-judges work best under human supervision.
Combining Query Performance Predictors: A Reproducibility Study
Mar 31, 2025



A large number of approaches to Query Performance Prediction (QPP) have been proposed over the last two decades. As early as 2009, Hauff et al. [28] explored whether different QPP methods may be combined to improve prediction quality. Since then, significant research has been done both on QPP approaches, as well as their evaluation. This study revisits Hauff et al.s work to assess the reproducibility of their findings in the light of new prediction methods, evaluation metrics, and datasets. We expand the scope of the earlier investigation by: (i) considering post-retrieval methods, including supervised neural techniques (only pre-retrieval techniques were studied in [28]); (ii) using sMARE for evaluation, in addition to the traditional correlation coefficients and RMSE; and (iii) experimenting with additional datasets (Clueweb09B and TREC DL). Our results largely support previous claims, but we also present several interesting findings. We interpret these findings by taking a more nuanced look at the correlation between QPP methods, examining whether they capture diverse information or rely on overlapping factors.
On the Feasibility and Robustness of Pointwise Evaluation of Query Performance Prediction
Apr 01, 2023Despite the retrieval effectiveness of queries being mutually independent of one another, the evaluation of query performance prediction (QPP) systems has been carried out by measuring rank correlation over an entire set of queries. Such a listwise approach has a number of disadvantages, notably that it does not support the common requirement of assessing QPP for individual queries. In this paper, we propose a pointwise QPP framework that allows us to evaluate the quality of a QPP system for individual queries by measuring the deviations between each prediction versus the corresponding true value, and then aggregating the results over a set of queries. Our experiments demonstrate that this new approach leads to smaller variances in QPP evaluations across a range of different target metrics and retrieval models.
Explainability of Text Processing and Retrieval Methods: A Critical Survey
Dec 14, 2022
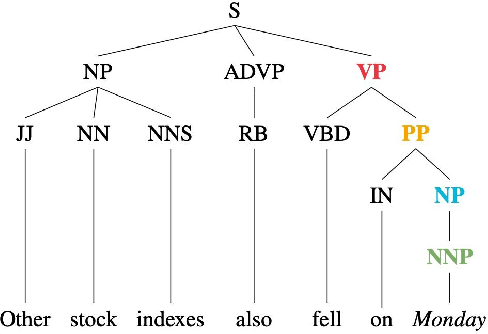
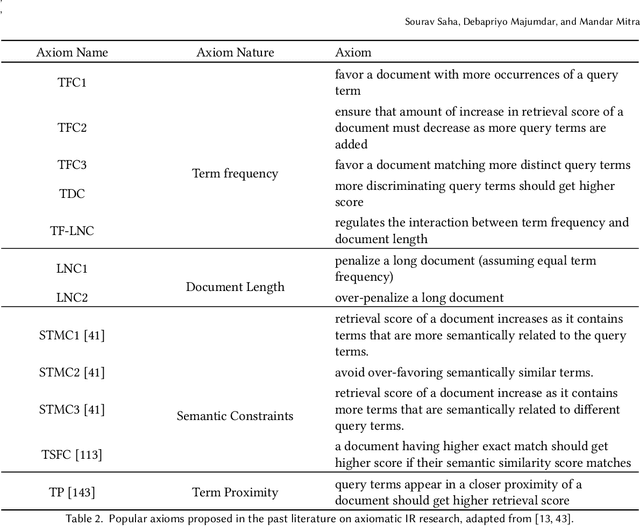
Deep Learning and Machine Learning based models have become extremely popular in text processing and information retrieval. However, the non-linear structures present inside the networks make these models largely inscrutable. A significant body of research has focused on increasing the transparency of these models. This article provides a broad overview of research on the explainability and interpretability of natural language processing and information retrieval methods. More specifically, we survey approaches that have been applied to explain word embeddings, sequence modeling, attention modules, transformers, BERT, and document ranking. The concluding section suggests some possible directions for future research on this topic.
Deep-QPP: A Pairwise Interaction-based Deep Learning Model for Supervised Query Performance Prediction
Feb 15, 2022
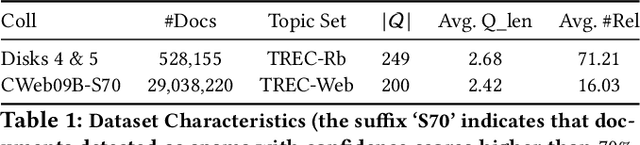
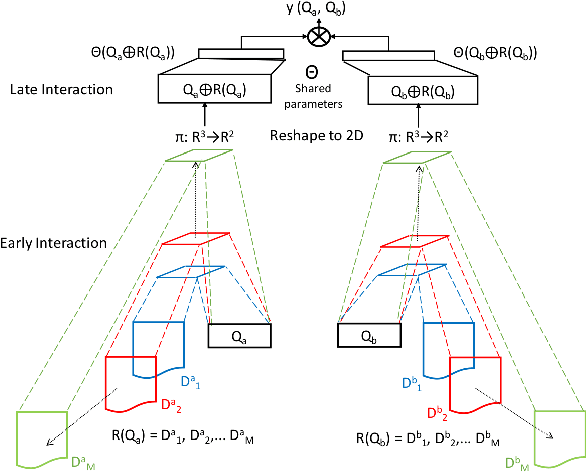
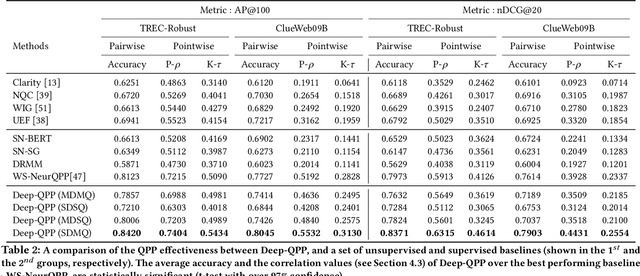
Motivated by the recent success of end-to-end deep neural models for ranking tasks, we present here a supervised end-to-end neural approach for query performance prediction (QPP). In contrast to unsupervised approaches that rely on various statistics of document score distributions, our approach is entirely data-driven. Further, in contrast to weakly supervised approaches, our method also does not rely on the outputs from different QPP estimators. In particular, our model leverages information from the semantic interactions between the terms of a query and those in the top-documents retrieved with it. The architecture of the model comprises multiple layers of 2D convolution filters followed by a feed-forward layer of parameters. Experiments on standard test collections demonstrate that our proposed supervised approach outperforms other state-of-the-art supervised and unsupervised approaches.
An Analysis of Variations in the Effectiveness of Query Performance Prediction
Feb 13, 2022
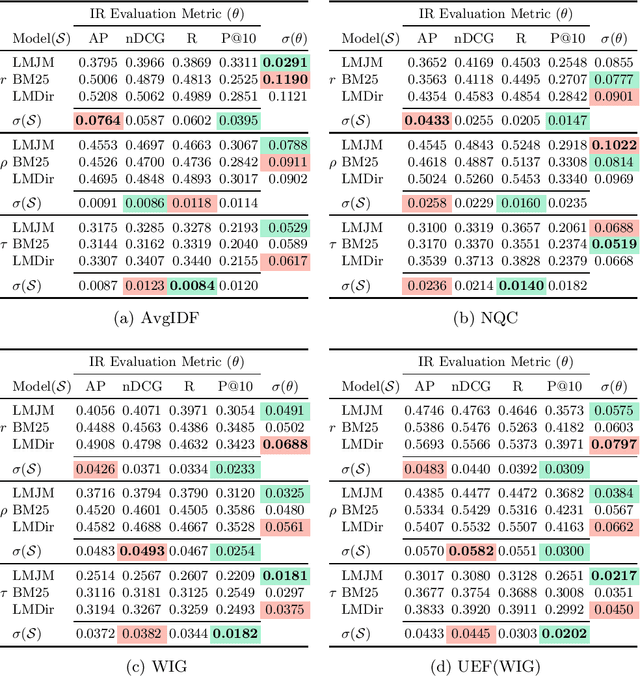
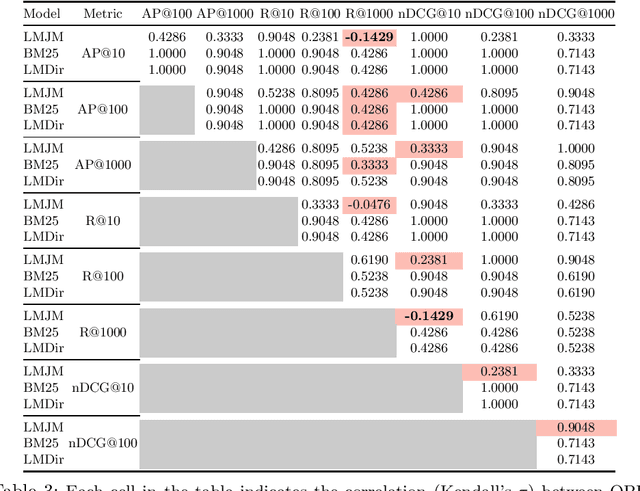
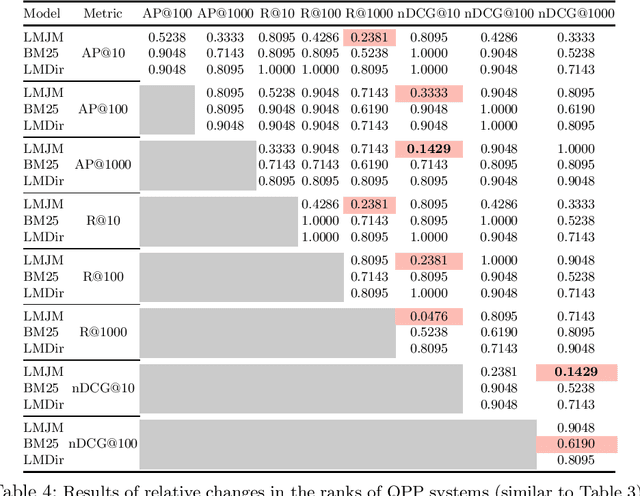
A query performance predictor estimates the retrieval effectiveness of an IR system for a given query. An important characteristic of QPP evaluation is that, since the ground truth retrieval effectiveness for QPP evaluation can be measured with different metrics, the ground truth itself is not absolute, which is in contrast to other retrieval tasks, such as that of ad-hoc retrieval. Motivated by this argument, the objective of this paper is to investigate how such variances in the ground truth for QPP evaluation can affect the outcomes of QPP experiments. We consider this not only in terms of the absolute values of the evaluation metrics being reported (e.g. Pearson's $r$, Kendall's $\tau$), but also with respect to the changes in the ranks of different QPP systems when ordered by the QPP metric scores. Our experiments reveal that the observed QPP outcomes can vary considerably, both in terms of the absolute evaluation metric values and also in terms of the relative system ranks. Through our analysis, we report the optimal combinations of QPP evaluation metric and experimental settings that are likely to lead to smaller variations in the observed results.
Re-evaluating the need for Modelling Term-Dependence in Text Classification Problems
Oct 25, 2017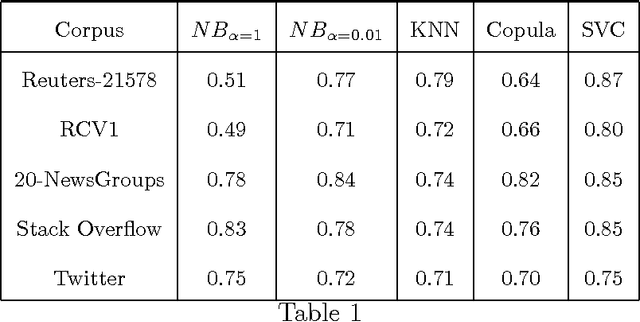
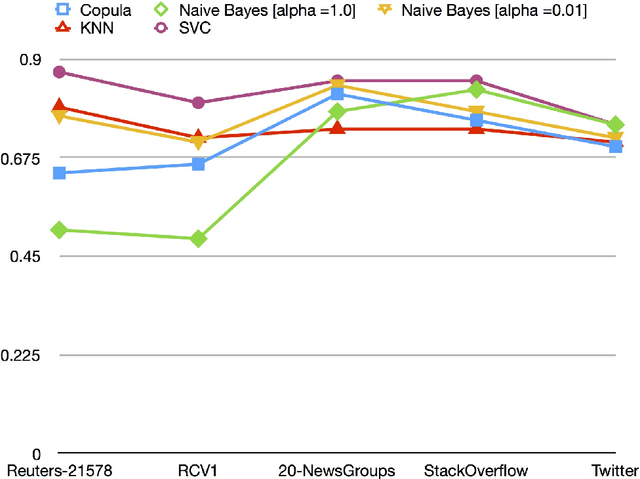
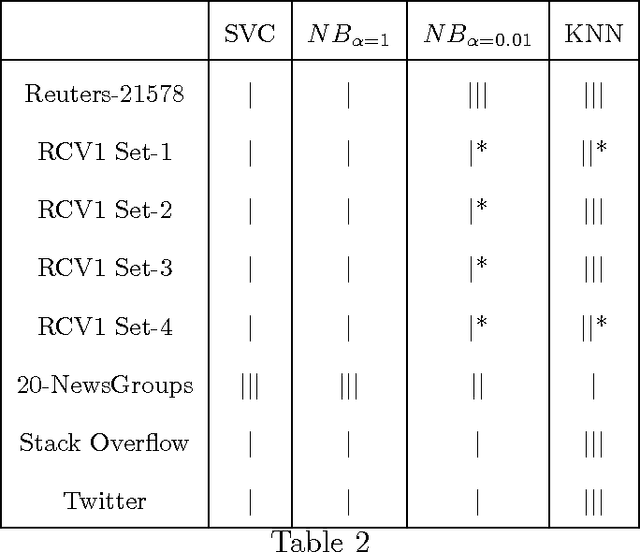
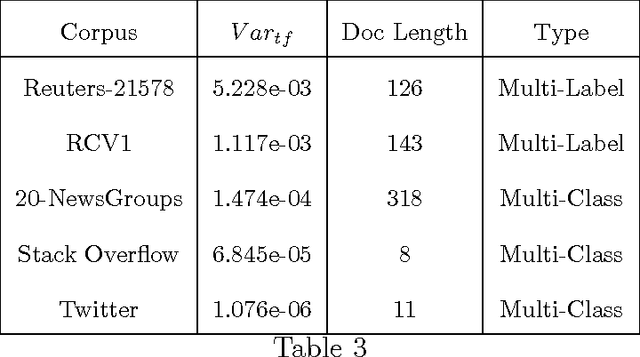
A substantial amount of research has been carried out in developing machine learning algorithms that account for term dependence in text classification. These algorithms offer acceptable performance in most cases but they are associated with a substantial cost. They require significantly greater resources to operate. This paper argues against the justification of the higher costs of these algorithms, based on their performance in text classification problems. In order to prove the conjecture, the performance of one of the best dependence models is compared to several well established algorithms in text classification. A very specific collection of datasets have been designed, which would best reflect the disparity in the nature of text data, that are present in real world applications. The results show that even one of the best term dependence models, performs decent at best when compared to other independence models. Coupled with their substantially greater requirement for hardware resources for operation, this makes them an impractical choice for being used in real world scenarios.