 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-evaluating the need for Modelling Term-Dependence in Text Classification Problems
Paper and Code
Oct 25, 2017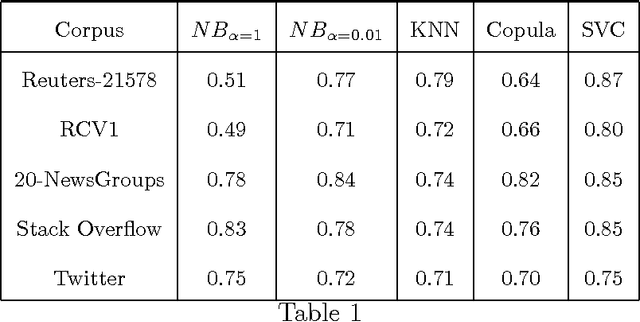
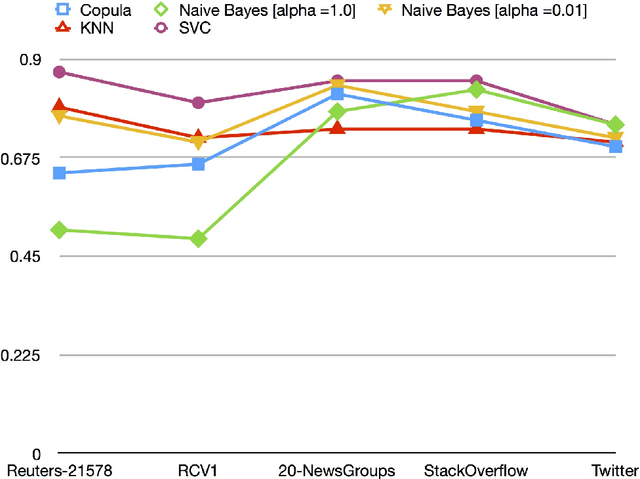
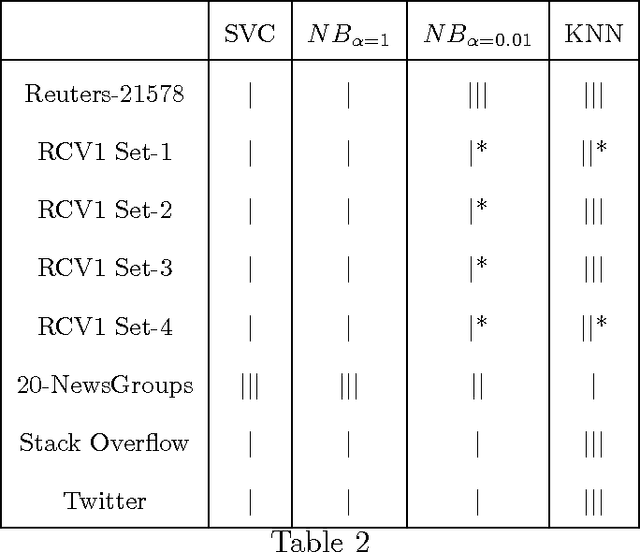
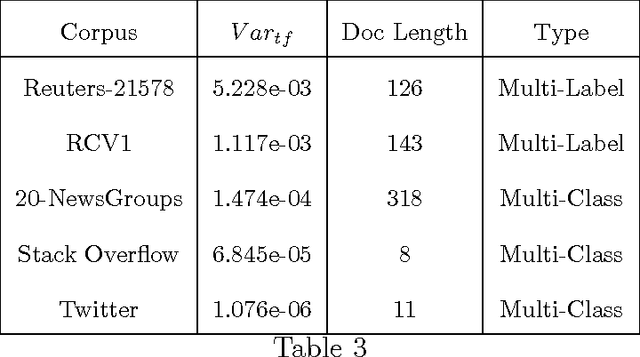
A substantial amount of research has been carried out in developing machine learning algorithms that account for term dependence in text classification. These algorithms offer acceptable performance in most cases but they are associated with a substantial cost. They require significantly greater resources to operate. This paper argues against the justification of the higher costs of these algorithms, based on their performance in text classification problems. In order to prove the conjecture, the performance of one of the best dependence models is compared to several well established algorithms in text classification. A very specific collection of datasets have been designed, which would best reflect the disparity in the nature of text data, that are present in real world applications. The results show that even one of the best term dependence models, performs decent at best when compared to other independence models. Coupled with their substantially greater requirement for hardware resources for operation, this makes them an impractical choice for being used in real world scenarios.