 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Variations in the Effectiveness of Query Performance Prediction
Paper and Code

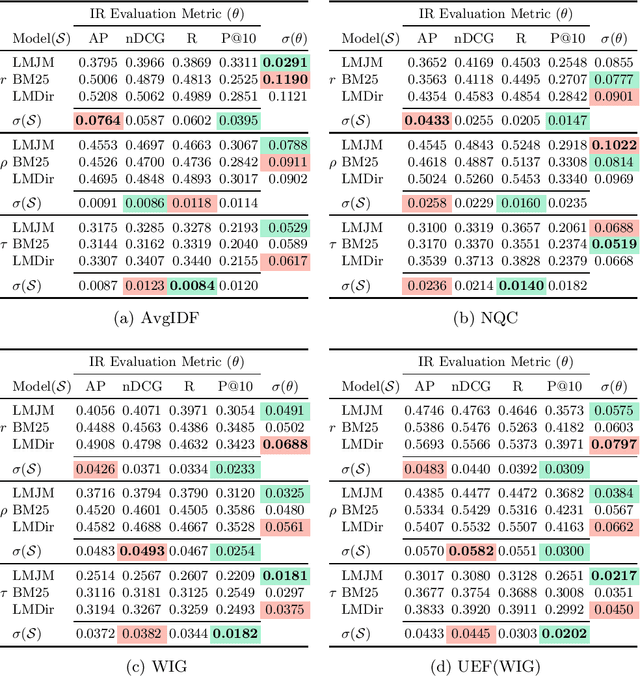
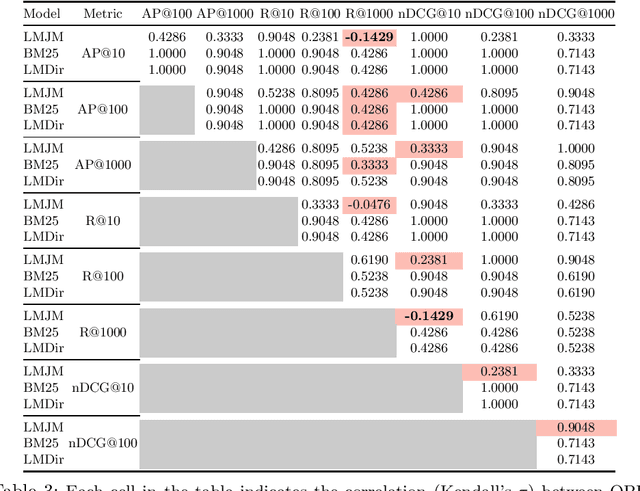
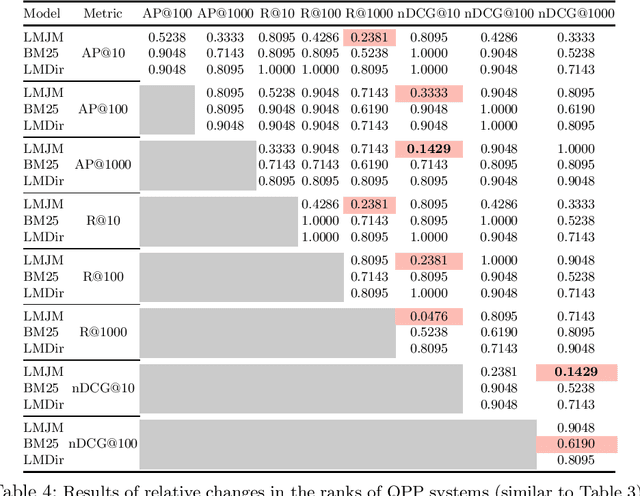
A query performance predictor estimates the retrieval effectiveness of an IR system for a given query. An important characteristic of QPP evaluation is that, since the ground truth retrieval effectiveness for QPP evaluation can be measured with different metrics, the ground truth itself is not absolute, which is in contrast to other retrieval tasks, such as that of ad-hoc retrieval. Motivated by this argument, the objective of this paper is to investigate how such variances in the ground truth for QPP evaluation can affect the outcomes of QPP experiments. We consider this not only in terms of the absolute values of the evaluation metrics being reported (e.g. Pearson's $r$, Kendall's $\tau$), but also with respect to the changes in the ranks of different QPP systems when ordered by the QPP metric scores. Our experiments reveal that the observed QPP outcomes can vary considerably, both in terms of the absolute evaluation metric values and also in terms of the relative system ranks. Through our analysis, we report the optimal combinations of QPP evaluation metric and experimental settings that are likely to lead to smaller variations in the observed results.