 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Presentation Style on Human-In-The-Loop Detection of Algorithmic Bias
May 09, 2020
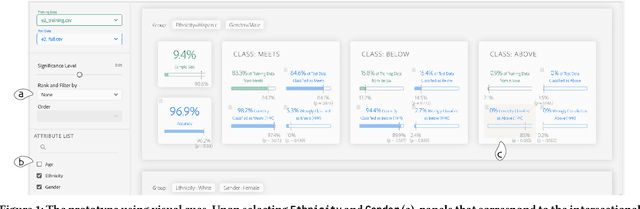
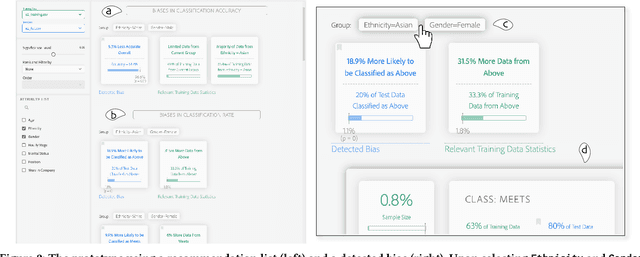

While decision makers have begun to employ machine learning, machine learning models may make predictions that bias against certain demographic groups. Semi-automated bias detection tools often present reports of automatically-detected biases using a recommendation list or visual cues. However, there is a lack of guidance concerning which presentation style to use in what scenarios. We conducted a small lab study with 16 participants to investigate how presentation style might affect user behaviors in reviewing bias reports. Participants used both a prototype with a recommendation list and a prototype with visual cues for bias detection. We found that participants often wanted to investigate the performance measures that were not automatically detected as biases. Yet, when using the prototype with a recommendation list, they tended to give less consideration to such measures. Grounded in the findings, we propose information load and comprehensiveness as two axes for characterizing bias detection tasks and illustrate how the two axes could be adopted to reason about when to use a recommendation list or visual cues.
Designing Tools for Semi-Automated Detection of Machine Learning Biases: An Interview Study
Mar 18, 2020Machine learning models often make predictions that bias against certain subgroups of input data. When undetected, machine learning biases can constitute significant financial and ethical implications. Semi-automated tools that involve humans in the loop could facilitate bias detection. Yet, little is known about the considerations involved in their design. In this paper, we report on an interview study with 11 machine learning practitioners for investigating the needs surrounding semi-automated bias detection tools. Based on the findings, we highlight four considerations in designing to guide system designers who aim to create future tools for bias detection.