 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Common Principal Subspace of Deep Features in Neural Networks
Paper and Code
Oct 06, 2021


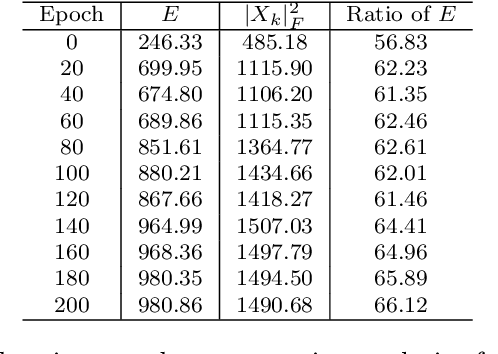
We find that different Deep Neural Networks (DNNs) trained with the same dataset share a common principal subspace in latent spaces, no matter in which architectures (e.g., Convolutional Neural Networks (CNNs), Multi-Layer Preceptors (MLPs) and Autoencoders (AEs)) the DNNs were built or even whether labels have been used in training (e.g., supervised, unsupervised, and self-supervised learning). Specifically, we design a new metric $\mathcal{P}$-vector to represent the principal subspace of deep features learned in a DNN, and propose to measure angles between the principal subspaces using $\mathcal{P}$-vectors. Small angles (with cosine close to $1.0$) have been found in the comparisons between any two DNNs trained with different algorithms/architectures. Furthermore, during the training procedure from random scratch, the angle decrease from a larger one ($70^\circ-80^\circ$ usually) to the small one, which coincides the progress of feature space learning from scratch to convergence. Then, we carry out case studies to measure the angle between the $\mathcal{P}$-vector and the principal subspace of training dataset, and connect such angle with generalization performance. Extensive experiments with practically-used Multi-Layer Perceptron (MLPs), AEs and CNNs for classification, image reconstruction, and self-supervised learning tasks on MNIST, CIFAR-10 and CIFAR-100 datasets have been done to support our claims with solid evidences. Interpretability of Deep Learning, Feature Learning, and Subspaces of Deep Features