 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Scalable Visual Servoing Using Deep Reinforcement Learning and Optimal Control
Oct 02, 2023Classical pixel-based Visual Servoing (VS) approaches offer high accuracy but suffer from a limited convergence area due to optimization nonlinearity. Modern deep learning-based VS methods overcome traditional vision issues but lack scalability, requiring training on limited scenes. This paper proposes a hybrid VS strategy utilizing Deep Reinforcement Learning (DRL) and optimal control to enhance both convergence area and scalability. The DRL component of our approach separately handles representation and policy learning to enhance scalability, generalizability, learning efficiency and ease domain adaptation. Moreover, the optimal control part ensures high end-point accuracy. Our method showcases remarkable achievements in terms of high convergence rates and minimal end-positioning errors using a 7-DOF manipulator. Importantly, it exhibits scalability across more than 1000 distinct scenes. Furthermore, we demonstrate its capacity for generalization to previously unseen datasets. Lastly, we illustrate the real-world applicability of our approach, highlighting its adaptability through single-shot domain transfer learning in environments with noise and occlusions. Real-robot experiments can be found at \url{https://sites.google.com/view/vsls}.
Least-Restrictive Multi-Agent Collision Avoidance via Deep Meta Reinforcement Learning and Optimal Control
Jun 02, 2021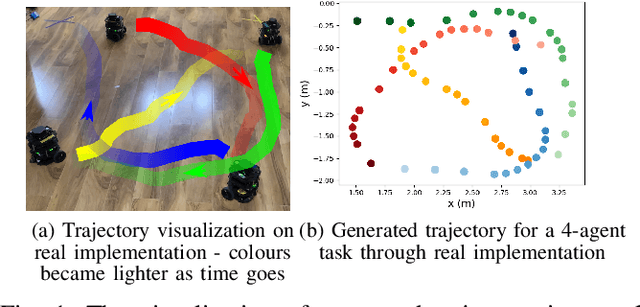
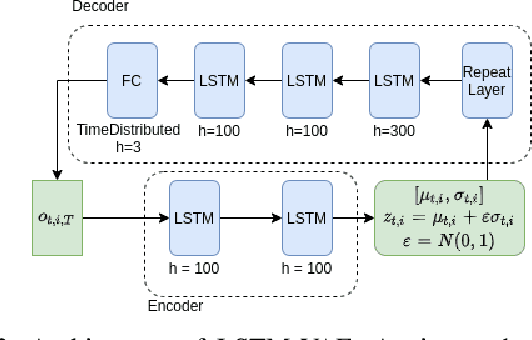
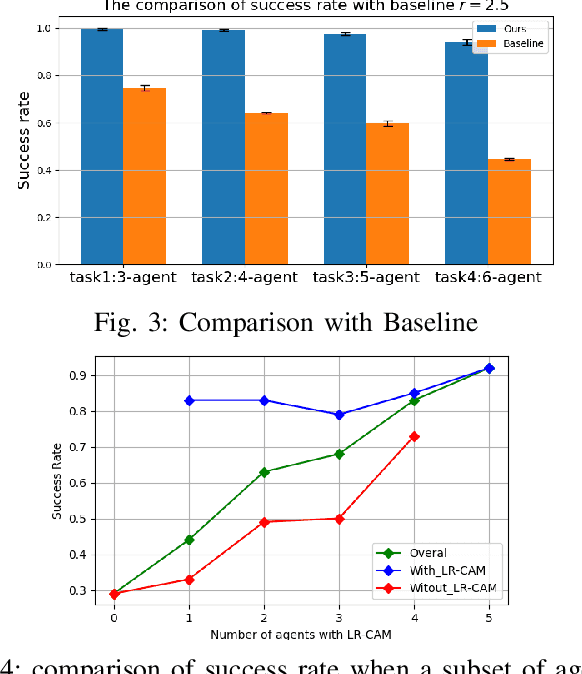

Multi-agent collision-free trajectory planning and control subject to different goal requirements and system dynamics has been extensively studied, and is gaining recent attention in the realm of machine and reinforcement learning. However, in particular when using a large number of agents, constructing a least-restrictive collision avoidance policy is of utmost importance for both classical and learning-based methods. In this paper, we propose a Least-Restrictive Collision Avoidance Module (LR-CAM) that evaluates the safety of multi-agent systems and takes over control only when needed to prevent collisions. The LR-CAM is a single policy that can be wrapped around policies of all agents in a multi-agent system. It allows each agent to pursue any objective as long as it is safe to do so. The benefit of the proposed least-restrictive policy is to only interrupt and overrule the default controller in case of an upcoming inevitable danger. We use a Long Short-Term Memory (LSTM) based Variational Auto-Encoder (VAE) to enable the LR-CAM to account for a varying number of agents in the environment. Moreover, we propose an off-policy meta-reinforcement learning framework with a novel reward function based on a Hamilton-Jacobi value function to train the LR-CAM. The proposed method is fully meta-trained through a ROS based simulation and tested on real multi-agent system. Our results show that LR-CAM outperforms the classical least-restrictive baseline by 30 percent. In addition, we show that even if a subset of agents in a multi-agent system use LR-CAM, the success rate of all agents will increase significantly.