 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Vision-Language Pretraining for Efficient Cross-Modal Retrieval
Paper and Code
May 23, 2024

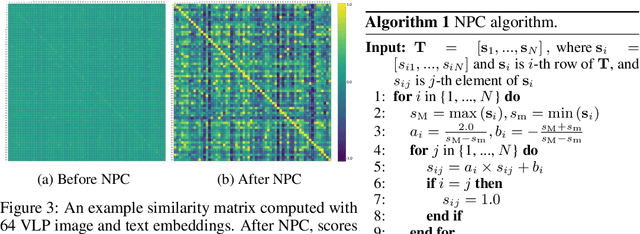
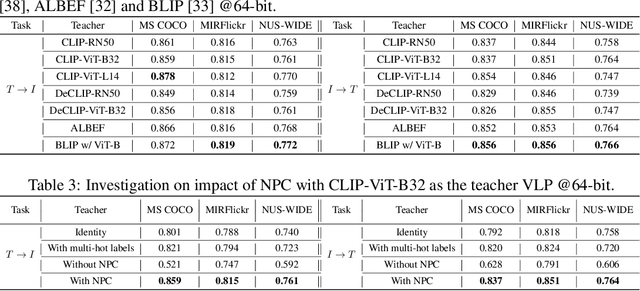
``Learning to hash'' is a practical solution for efficient retrieval, offering fast search speed and low storage cost. It is widely applied in various applications, such as image-text cross-modal search. In this paper, we explore the potential of enhancing the performance of learning to hash with the proliferation of powerful large pre-trained models, such as Vision-Language Pre-training (VLP) models. We introduce a novel method named Distillation for Cross-Modal Quantization (DCMQ), which leverages the rich semantic knowledge of VLP models to improve hash representation learning. Specifically, we use the VLP as a `teacher' to distill knowledge into a `student' hashing model equipped with codebooks. This process involves the replacement of supervised labels, which are composed of multi-hot vectors and lack semantics, with the rich semantics of VLP. In the end, we apply a transformation termed Normalization with Paired Consistency (NPC) to achieve a discriminative target for distillation. Further, we introduce a new quantization method, Product Quantization with Gumbel (PQG) that promotes balanced codebook learning, thereby improving the retrieval performance. Extensive benchmark testing demonstrates that DCMQ consistently outperforms existing supervised cross-modal hashing approaches, showcasing its significant potential.