 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Similar Exercises in Retrieval Manner
Mar 15, 2023


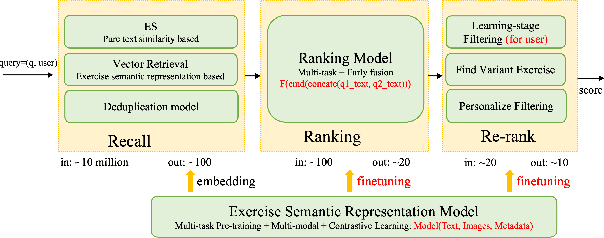
When students make a mistake in an exercise, they can consolidate it by ``similar exercises'' which have the same concepts, purposes and methods. Commonly, for a certain subject and study stage, the size of the exercise bank is in the range of millions to even tens of millions, how to find similar exercises for a given exercise becomes a crucial technical problem. Generally, we can assign a variety of explicit labels to the exercise, and then query through the labels, but the label annotation is time-consuming, laborious and costly, with limited precision and granularity, so it is not feasible. In practice, we define ``similar exercises'' as a retrieval process of finding a set of similar exercises based on recall, ranking and re-rank procedures, called the \textbf{FSE} problem (Finding similar exercises). Furthermore, comprehensive representation of the semantic information of exercises was obtained through representation learning. In addition to the reasonable architecture, we also explore what kind of tasks are more conducive to the learning of exercise semantic information from pre-training and supervised learning. It is difficult to annotate similar exercises and the annotation consistency among experts is low. Therefore this paper also provides solutions to solve the problem of low-quality annotated data. Compared with other methods, this paper has obvious advantages in both architecture rationality and algorithm precision, which now serves the daily teaching of hundreds of schools.
* 37th Conference on AAAI 2023 Artificial Intelligence for Education(AI4Edu)
TQ-Net: Mixed Contrastive Representation Learning For Heterogeneous Test Questions
Mar 09, 2023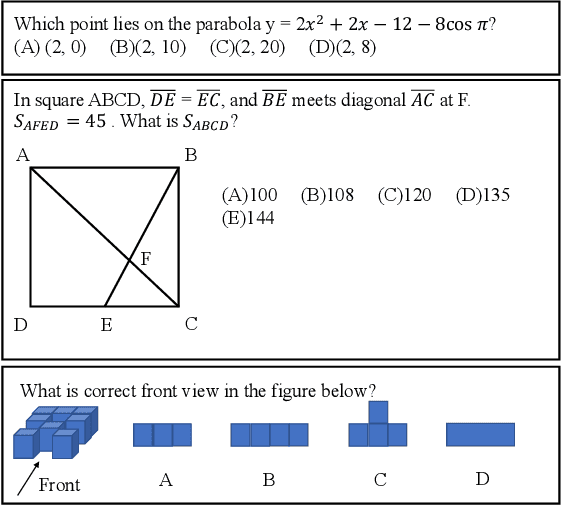

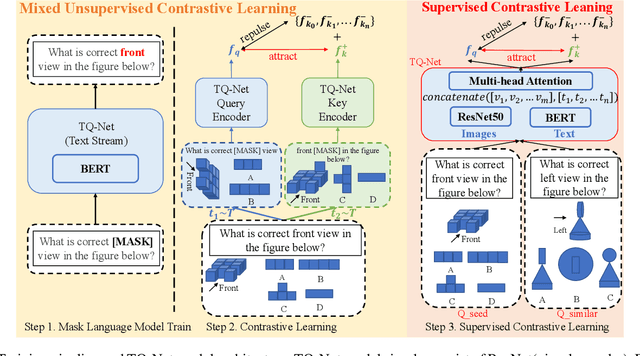
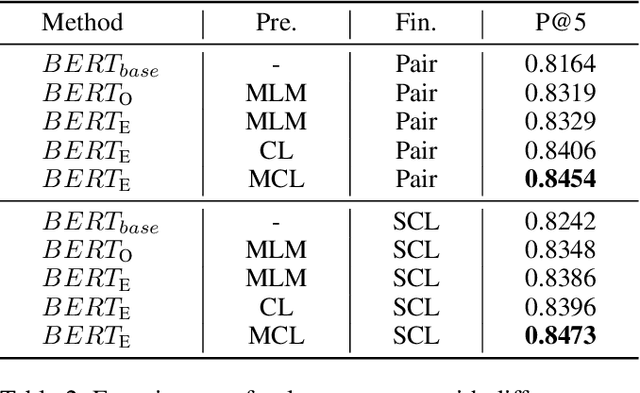
Recently, more and more people study online for the convenience of access to massive learning materials (e.g. test questions/notes), thus accurately understanding learning materials became a crucial issue, which is essential for many educational applications. Previous studies focus on using language models to represent the question data. However, test questions (TQ) are usually heterogeneous and multi-modal, e.g., some of them may only contain text, while others half contain images with information beyond their literal description. In this context, both supervised and unsupervised methods are difficult to learn a fused representation of questions. Meanwhile, this problem cannot be solved by conventional methods such as image caption, as the images may contain information complementary rather than duplicate to the text. In this paper, we first improve previous text-only representation with a two-stage unsupervised instance level contrastive based pre-training method (MCL: Mixture Unsupervised Contrastive Learning). Then, TQ-Net was proposed to fuse the content of images to the representation of heterogeneous data. Finally, supervised contrastive learning was conducted on relevance prediction-related downstream tasks, which helped the model to learn the representation of questions effectively. We conducted extensive experiments on question-based tasks on large-scale, real-world datasets, which demonstrated the effectiveness of TQ-Net and improve the precision of downstream applications (e.g. similar questions +2.02% and knowledge point prediction +7.20%). Our code will be available, and we will open-source a subset of our data to promote the development of relative studies.
Exploring Student Representation For Neural Cognitive Diagnosis
Nov 17, 2021


Cognitive diagnosis, the goal of which is to obtain the proficiency level of students on specific knowledge concepts, is an fundamental task in smart educational systems. Previous works usually represent each student as a trainable knowledge proficiency vector, which cannot capture the relations of concepts and the basic profile(e.g. memory or comprehension) of students. In this paper, we propose a method of student representation with the exploration of the hierarchical relations of knowledge concepts and student embedding. Specifically, since the proficiency on parent knowledge concepts reflects the correlation between knowledge concepts, we get the first knowledge proficiency with a parent-child concepts projection layer. In addition, a low-dimension dense vector is adopted as the embedding of each student, and obtain the second knowledge proficiency with a full connection layer. Then, we combine the two proficiency vector above to get the final representation of students. Experiments show the effectiveness of proposed representation method.
An Empirical Study of Finding Similar Exercises
Nov 16, 2021



Education artificial intelligence aims to profit tasks in the education domain such as intelligent test paper generation and consolidation exercises where the main technique behind is how to match the exercises, known as the finding similar exercises(FSE) problem. Most of these approaches emphasized their model abilities to represent the exercise, unfortunately there are still many challenges such as the scarcity of data, insufficient understanding of exercises and high label noises. We release a Chinese education pre-trained language model BERT$_{Edu}$ for the label-scarce dataset and introduce the exercise normalization to overcome the diversity of mathematical formulas and terms in exercise. We discover new auxiliary tasks in an innovative way depends on problem-solving ideas and propose a very effective MoE enhanced multi-task model for FSE task to attain better understanding of exercises. In addition, confidence learning was utilized to prune train-set and overcome high noises in labeling data. Experiments show that these methods proposed in this paper are very effective.
* 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Workshop on Math AI for Education(MATHAI4ED)
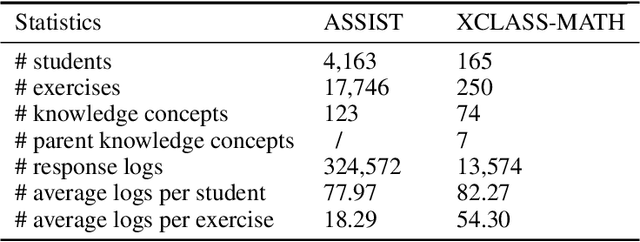
LANA: Towards Personalized Deep Knowledge Tracing Through Distinguishable Interactive Sequences
Apr 21, 2021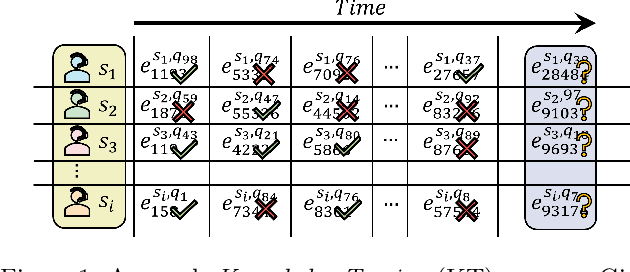

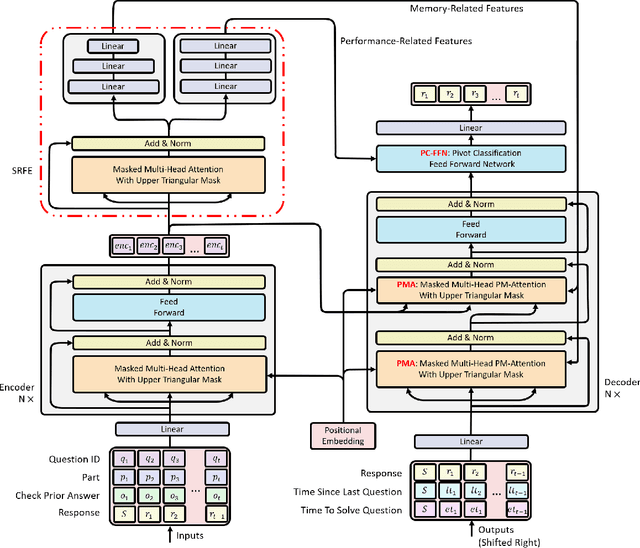
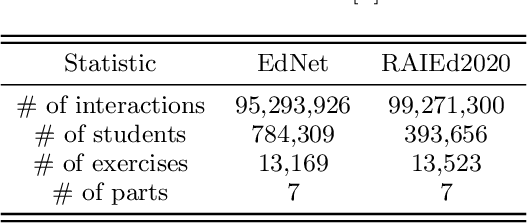
In educational applications, Knowledge Tracing (KT), the problem of accurately predicting students' responses to future questions by summarizing their knowledge states, has been widely studied for decades as it is considered a fundamental task towards adaptive online learning. Among all the proposed KT methods, Deep Knowledge Tracing (DKT) and its variants are by far the most effective ones due to the high flexibility of the neural network. However, DKT often ignores the inherent differences between students (e.g. memory skills, reasoning skills, ...), averaging the performances of all students, leading to the lack of personalization, and therefore was considered insufficient for adaptive learning. To alleviate this problem, in this paper, we proposed Leveled Attentive KNowledge TrAcing (LANA), which firstly uses a novel student-related features extractor (SRFE) to distill students' unique inherent properties from their respective interactive sequences. Secondly, the pivot module was utilized to dynamically reconstruct the decoder of the neural network on attention of the extracted features, successfully distinguishing the performance between students over time. Moreover, inspired by Item Response Theory (IRT), the interpretable Rasch model was used to cluster students by their ability levels, and thereby utilizing leveled learning to assign different encoders to different groups of students. With pivot module reconstructed the decoder for individual students and leveled learning specialized encoders for groups, personalized DKT was achieved. Extensive experiments conducted on two real-world large-scale datasets demonstrated that our proposed LANA improves the AUC score by at least 1.00% (i.e. EdNet 1.46% and RAIEd2020 1.00%), substantially surpassing the other State-Of-The-Art KT methods.
Improving precision and recall of face recognition in SIPP with combination of modified mean search and LSH
Feb 27, 2018
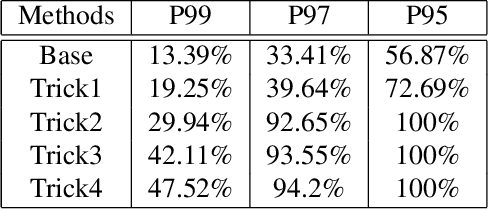
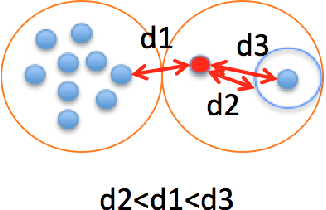

Although face recognition has been improved much as the development of Deep Neural Networks, SIPP(Single Image Per Person) problem in face recognition has not been better solved, especially in practical applications where searching over complicated database. In this paper, a combination of modified mean search and LSH method would be introduced orderly to improve the precision and recall of SIPP face recognition without retrain of the DNN model. First, a modified SVD based augmentation method would be introduced to get more intra-class variations even for person with only one image. Second, an unique rule based combination of modified mean search and LSH method was proposed the first time to help get the most similar personID in a complicated dataset, and some theoretical explaining followed. Third, we would like to emphasize, no need to retrain of the DNN model and would easy to be extended without much efforts. We do some practical testing in competition of Msceleb challenge-2 2017 which was hold by Microsoft Research, great improvement of coverage from 13.39% to 19.25%, 29.94%, 42.11%, 47.52% at precision 99%(P99) would be shown latter, coverage reach 94.2% and 100% at precision 97%(P97) and 95%(P95) respectively. As far as we known, this is the only paper who do not fine-tuning on competition dataset and ranked top-10. A similar test on CASIA WebFace dataset also demonstrated the same improvements on both precision and recall.