 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothSinger: A Conditional Diffusion Model for Singing Voice Synthesis with Multi-Resolution Architecture
Jun 26, 2025Singing voice synthesis (SVS) aims to generate expressive and high-quality vocals from musical scores, requiring precise modeling of pitch, duration, and articulation. While diffusion-based models have achieved remarkable success in image and video generation, their application to SVS remains challenging due to the complex acoustic and musical characteristics of singing, often resulting in artifacts that degrade naturalness. In this work, we propose SmoothSinger, a conditional diffusion model designed to synthesize high quality and natural singing voices. Unlike prior methods that depend on vocoders as a final stage and often introduce distortion, SmoothSinger refines low-quality synthesized audio directly in a unified framework, mitigating the degradation associated with two-stage pipelines. The model adopts a reference-guided dual-branch architecture, using low-quality audio from any baseline system as a reference to guide the denoising process, enabling more expressive and context-aware synthesis. Furthermore, it enhances the conventional U-Net with a parallel low-frequency upsampling path, allowing the model to better capture pitch contours and long term spectral dependencies. To improve alignment during training, we replace reference audio with degraded ground truth audio, addressing temporal mismatch between reference and target signals. Experiments on the Opencpop dataset, a large-scale Chinese singing corpus, demonstrate that SmoothSinger achieves state-of-the-art results in both objective and subjective evaluations. Extensive ablation studies confirm its effectiveness in reducing artifacts and improving the naturalness of synthesized voices.
Make-It-Animatable: An Efficient Framework for Authoring Animation-Ready 3D Characters
Nov 27, 2024



3D characters are essential to modern creative industries, but making them animatable often demands extensive manual work in tasks like rigging and skinning. Existing automatic rigging tools face several limitations, including the necessity for manual annotations, rigid skeleton topologies, and limited generalization across diverse shapes and poses. An alternative approach is to generate animatable avatars pre-bound to a rigged template mesh. However, this method often lacks flexibility and is typically limited to realistic human shapes. To address these issues, we present Make-It-Animatable, a novel data-driven method to make any 3D humanoid model ready for character animation in less than one second, regardless of its shapes and poses. Our unified framework generates high-quality blend weights, bones, and pose transformations. By incorporating a particle-based shape autoencoder, our approach supports various 3D representations, including meshes and 3D Gaussian splats. Additionally, we employ a coarse-to-fine representation and a structure-aware modeling strategy to ensure both accuracy and robustness, even for characters with non-standard skeleton structures. We conducted extensive experiments to validate our framework's effectiveness. Compared to existing methods, our approach demonstrates significant improvements in both quality and speed.
RDSinger: Reference-based Diffusion Network for Singing Voice Synthesis
Oct 29, 2024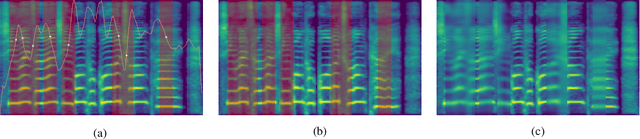

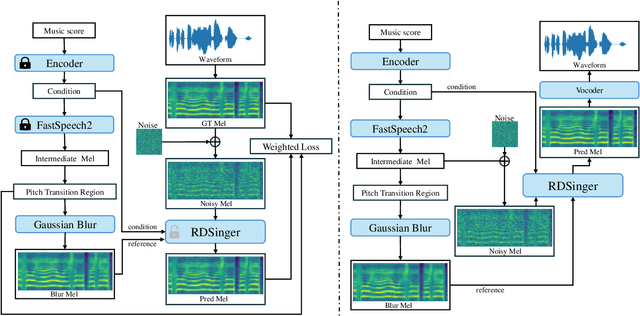

Singing voice synthesis (SVS) aims to produce high-fidelity singing audio from music scores, requiring a detailed understanding of notes, pitch, and duration, unlike text-to-speech tasks. Although diffusion models have shown exceptional performance in various generative tasks like image and video creation, their application in SVS is hindered by time complexity and the challenge of capturing acoustic features, particularly during pitch transitions. Some networks learn from the prior distribution and use the compressed latent state as a better start in the diffusion model, but the denoising step doesn't consistently improve quality over the entire duration. We introduce RDSinger, a reference-based denoising diffusion network that generates high-quality audio for SVS tasks. Our approach is inspired by Animate Anyone, a diffusion image network that maintains intricate appearance features from reference images. RDSinger utilizes FastSpeech2 mel-spectrogram as a reference to mitigate denoising step artifacts. Additionally, existing models could be influenced by misleading information on the compressed latent state during pitch transitions. We address this issue by applying Gaussian blur on partial reference mel-spectrogram and adjusting loss weights in these regions. Extensive ablation studies demonstrate the efficiency of our method. Evaluations on OpenCpop, a Chinese singing dataset, show that RDSinger outperforms current state-of-the-art SVS methods in performance.
Neural Impostor: Editing Neural Radiance Fields with Explicit Shape Manipulation
Oct 09, 2023Neural Radiance Fields (NeRF) have significantly advanced the generation of highly realistic and expressive 3D scenes. However, the task of editing NeRF, particularly in terms of geometry modification, poses a significant challenge. This issue has obstructed NeRF's wider adoption across various applications. To tackle the problem of efficiently editing neural implicit fields, we introduce Neural Impostor, a hybrid representation incorporating an explicit tetrahedral mesh alongside a multigrid implicit field designated for each tetrahedron within the explicit mesh. Our framework bridges the explicit shape manipulation and the geometric editing of implicit fields by utilizing multigrid barycentric coordinate encoding, thus offering a pragmatic solution to deform, composite, and generate neural implicit fields while maintaining a complex volumetric appearance. Furthermore, we propose a comprehensive pipeline for editing neural implicit fields based on a set of explicit geometric editing operations. We show the robustness and adaptability of our system through diverse examples and experiments, including the editing of both synthetic objects and real captured data. Finally, we demonstrate the authoring process of a hybrid synthetic-captured object utilizing a variety of editing operations, underlining the transformative potential of Neural Impostor in the field of 3D content creation and manipulation.
CROM: Continuous Reduced-Order Modeling of PDEs Using Implicit Neural Representations
Jun 06, 2022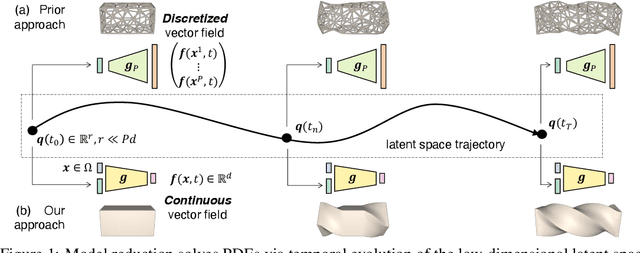
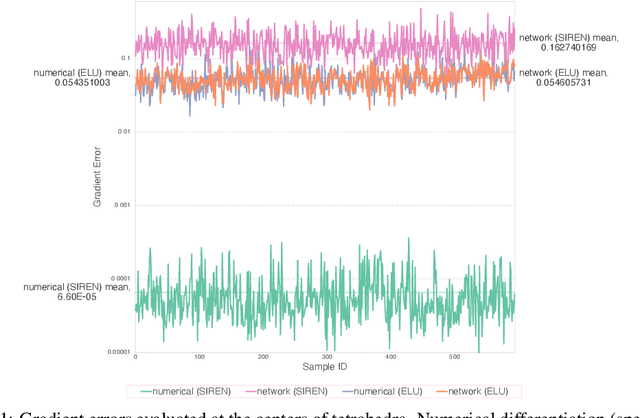
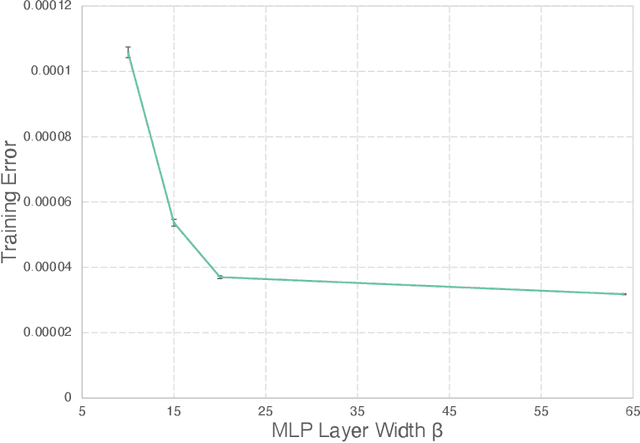

The excessive runtime of high-fidelity partial differential equation (PDE) solvers makes them unsuitable for time-critical applications. We propose to accelerate PDE solvers using reduced-order modeling (ROM). Whereas prior ROM approaches reduce the dimensionality of discretized vector fields, our continuous reduced-order modeling (CROM) approach builds a smooth, low-dimensional manifold of the continuous vector fields themselves, not their discretization. We represent this reduced manifold using neural fields, relying on their continuous and differentiable nature to efficiently solve the PDEs. CROM may train on any and all available numerical solutions of the continuous system, even when they are obtained using diverse methods or discretizations. After the low-dimensional manifolds are built, solving PDEs requires significantly less computational resources. Since CROM is discretization-agnostic, CROM-based PDE solvers may optimally adapt discretization resolution over time to economize computation. We validate our approach on an extensive range of PDEs with training data from voxel grids, meshes, and point clouds. Large-scale experiments demonstrate that our approach obtains speed, memory, and accuracy advantages over prior ROM approaches while gaining 109$\times$ wall-clock speedup over full-order models on CPUs and 89$\times$ speedup on GPUs.