 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDSinger: Reference-based Diffusion Network for Singing Voice Synthesis
Paper and Code
Oct 29, 2024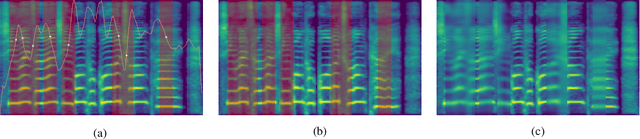

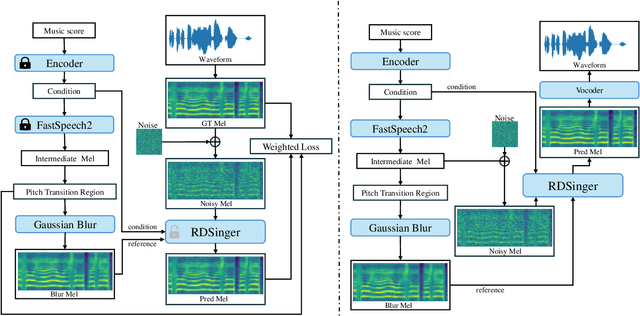

Singing voice synthesis (SVS) aims to produce high-fidelity singing audio from music scores, requiring a detailed understanding of notes, pitch, and duration, unlike text-to-speech tasks. Although diffusion models have shown exceptional performance in various generative tasks like image and video creation, their application in SVS is hindered by time complexity and the challenge of capturing acoustic features, particularly during pitch transitions. Some networks learn from the prior distribution and use the compressed latent state as a better start in the diffusion model, but the denoising step doesn't consistently improve quality over the entire duration. We introduce RDSinger, a reference-based denoising diffusion network that generates high-quality audio for SVS tasks. Our approach is inspired by Animate Anyone, a diffusion image network that maintains intricate appearance features from reference images. RDSinger utilizes FastSpeech2 mel-spectrogram as a reference to mitigate denoising step artifacts. Additionally, existing models could be influenced by misleading information on the compressed latent state during pitch transitions. We address this issue by applying Gaussian blur on partial reference mel-spectrogram and adjusting loss weights in these regions. Extensive ablation studies demonstrate the efficiency of our method. Evaluations on OpenCpop, a Chinese singing dataset, show that RDSinger outperforms current state-of-the-art SVS methods in performance.