Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered Diffusion Model for One-Shot High Resolution Text-to-Image Synthesis
Paper and Code
Jul 08, 2024
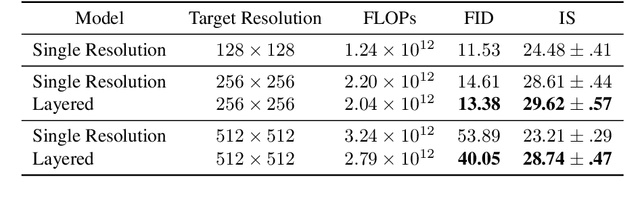


We present a one-shot text-to-image diffusion model that can generate high-resolution images from natural language descriptions. Our model employs a layered U-Net architecture that simultaneously synthesizes images at multiple resolution scales. We show that this method outperforms the baseline of synthesizing images only at the target resolution, while reducing the computational cost per step. We demonstrate that higher resolution synthesis can be achieved by layering convolutions at additional resolution scales, in contrast to other methods which require additional models for super-resolution synthesis.
View paper on