 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Teaching Humans Subtle Differences with DIFFusion
Apr 10, 2025
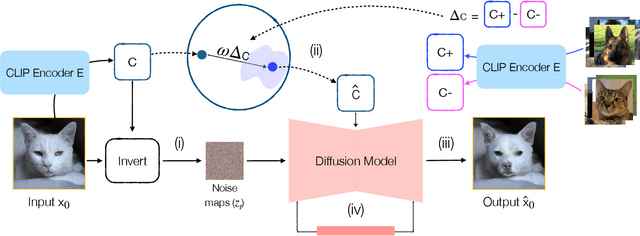


Human expertise depends on the ability to recognize subtle visual differences, such as distinguishing diseases, species, or celestial phenomena. We propose a new method to teach novices how to differentiate between nuanced categories in specialized domains. Our method uses generative models to visualize the minimal change in features to transition between classes, i.e., counterfactuals, and performs well even in domains where data is sparse, examples are unpaired, and category boundaries are not easily explained by text. By manipulating the conditioning space of diffusion models, our proposed method DIFFusion disentangles category structure from instance identity, enabling high-fidelity synthesis even in challenging domains. Experiments across six domains show accurate transitions even with limited and unpaired examples across categories. User studies confirm that our generated counterfactuals outperform unpaired examples in teaching perceptual expertise, showing the potential of generative models for specialized visual learning.
Evolving Interpretable Visual Classifiers with Large Language Models
Apr 15, 2024
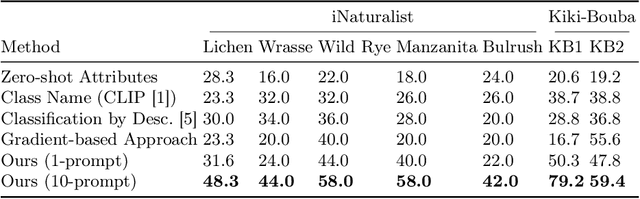


Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
Muscles in Action
Dec 05, 2022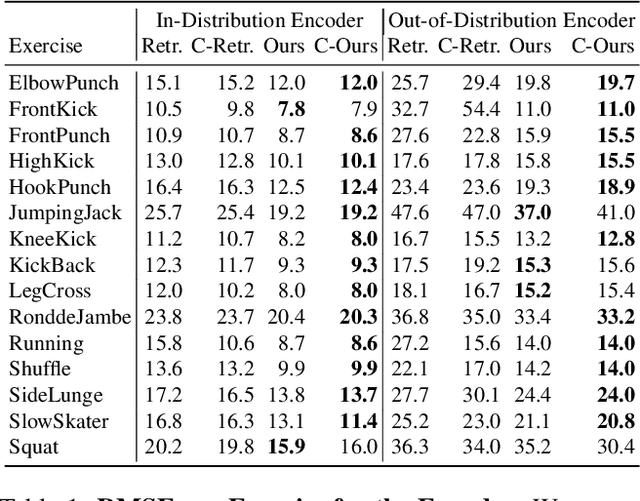

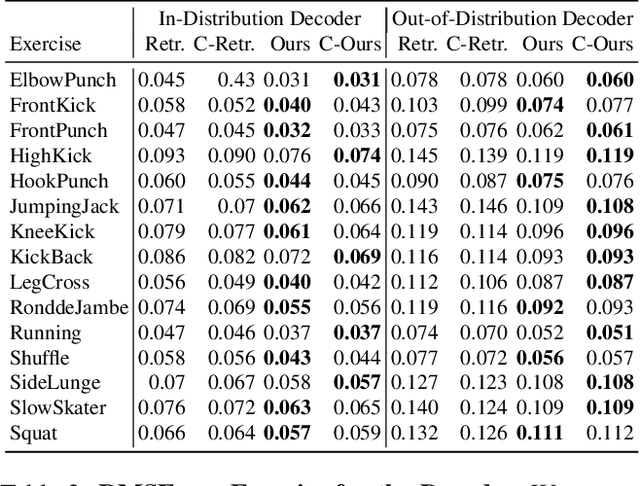

Small differences in a person's motion can engage drastically different muscles. While most visual representations of human activity are trained from video, people learn from multimodal experiences, including from the proprioception of their own muscles. We present a new visual perception task and dataset to model muscle activation in human activities from monocular video. Our Muscles in Action (MIA) dataset consists of 2 hours of synchronized video and surface electromyography (sEMG) data of subjects performing various exercises. Using this dataset, we learn visual representations that are predictive of muscle activation from monocular video. We present several models, including a transformer model, and measure their ability to generalize to new exercises and subjects. Putting muscles into computer vision systems will enable richer models of virtual humans, with applications in sports, fitness, and AR/VR.
Private Multiparty Perception for Navigation
Dec 02, 2022We introduce a framework for navigating through cluttered environments by connecting multiple cameras together while simultaneously preserving privacy. Occlusions and obstacles in large environments are often challenging situations for navigation agents because the environment is not fully observable from a single camera view. Given multiple camera views of an environment, our approach learns to produce a multiview scene representation that can only be used for navigation, provably preventing one party from inferring anything beyond the output task. On a new navigation dataset that we will publicly release, experiments show that private multiparty representations allow navigation through complex scenes and around obstacles while jointly preserving privacy. Our approach scales to an arbitrary number of camera viewpoints. We believe developing visual representations that preserve privacy is increasingly important for many applications such as navigation.
Real-Time Neural Voice Camouflage
Dec 14, 2021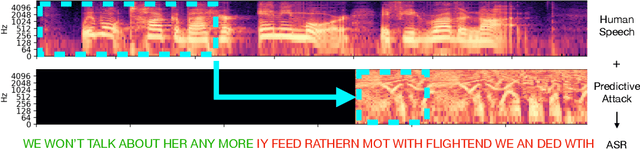
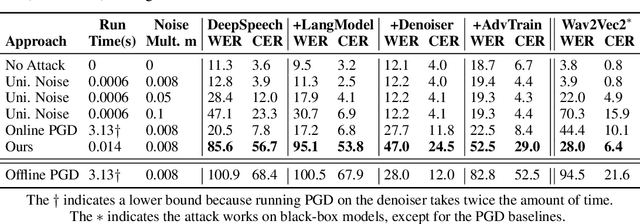
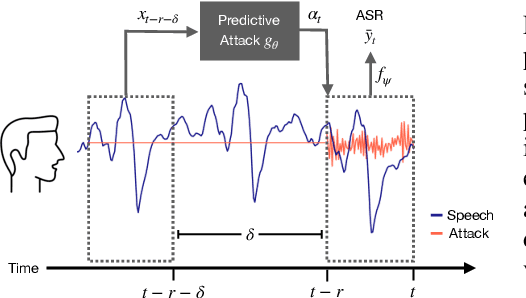

Automatic speech recognition systems have created exciting possibilities for applications, however they also enable opportunities for systematic eavesdropping. We propose a method to camouflage a person's voice over-the-air from these systems without inconveniencing the conversation between people in the room. Standard adversarial attacks are not effective in real-time streaming situations because the characteristics of the signal will have changed by the time the attack is executed. We introduce predictive attacks, which achieve real-time performance by forecasting the attack that will be the most effective in the future. Under real-time constraints, our method jams the established speech recognition system DeepSpeech 4.17x more than baselines as measured through word error rate, and 7.27x more as measured through character error rate. We furthermore demonstrate our approach is practically effective in realistic environments over physical distances.
The Boombox: Visual Reconstruction from Acoustic Vibrations
May 17, 2021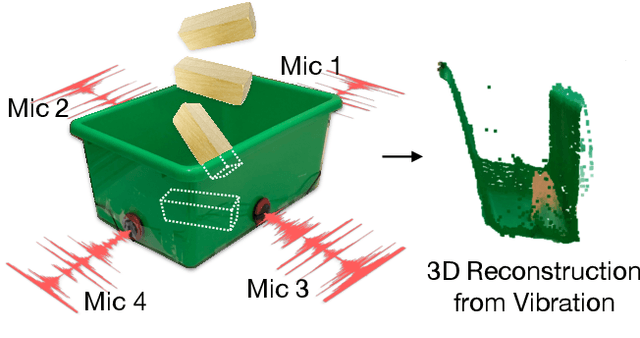
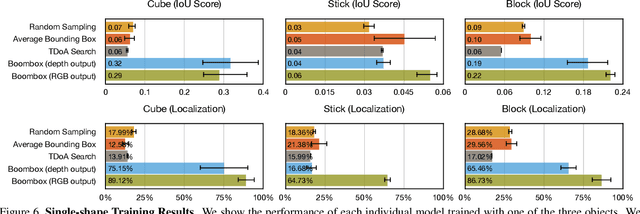
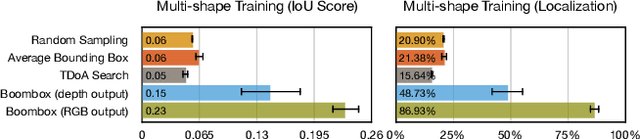
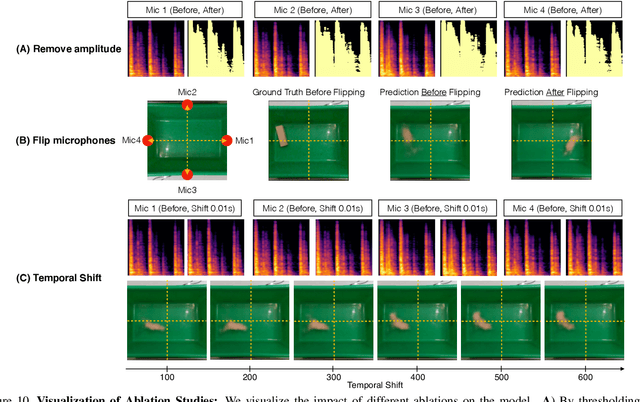
We introduce The Boombox, a container that uses acoustic vibrations to reconstruct an image of its inside contents. When an object interacts with the container, they produce small acoustic vibrations. The exact vibration characteristics depend on the physical properties of the box and the object. We demonstrate how to use this incidental signal in order to predict visual structure. After learning, our approach remains effective even when a camera cannot view inside the box. Although we use low-cost and low-power contact microphones to detect the vibrations, our results show that learning from multi-modal data enables us to transform cheap acoustic sensors into rich visual sensors. Due to the ubiquity of containers, we believe integrating perception capabilities into them will enable new applications in human-computer interaction and robotics. Our project website is at: boombox.cs.columbia.edu
Adversarial Attacks are Reversible with Natural Supervision
Mar 29, 2021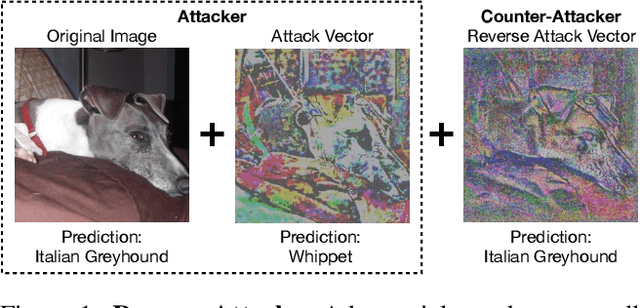
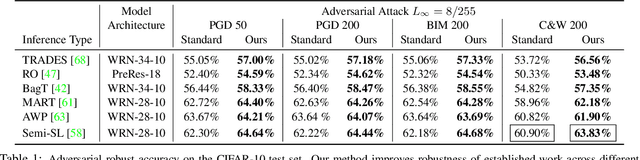
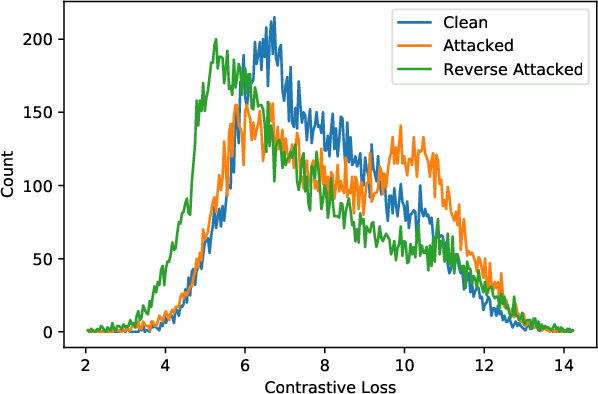

We find that images contain intrinsic structure that enables the reversal of many adversarial attacks. Attack vectors cause not only image classifiers to fail, but also collaterally disrupt incidental structure in the image. We demonstrate that modifying the attacked image to restore the natural structure will reverse many types of attacks, providing a defense. Experiments demonstrate significantly improved robustness for several state-of-the-art models across the CIFAR-10, CIFAR-100, SVHN, and ImageNet datasets. Our results show that our defense is still effective even if the attacker is aware of the defense mechanism. Since our defense is deployed during inference instead of training, it is compatible with pre-trained networks as well as most other defenses. Our results suggest deep networks are vulnerable to adversarial examples partly because their representations do not enforce the natural structure of images.