 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Humans Subtle Differences with DIFFusion
Apr 10, 2025
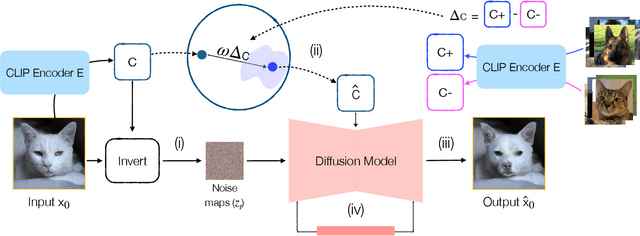


Human expertise depends on the ability to recognize subtle visual differences, such as distinguishing diseases, species, or celestial phenomena. We propose a new method to teach novices how to differentiate between nuanced categories in specialized domains. Our method uses generative models to visualize the minimal change in features to transition between classes, i.e., counterfactuals, and performs well even in domains where data is sparse, examples are unpaired, and category boundaries are not easily explained by text. By manipulating the conditioning space of diffusion models, our proposed method DIFFusion disentangles category structure from instance identity, enabling high-fidelity synthesis even in challenging domains. Experiments across six domains show accurate transitions even with limited and unpaired examples across categories. User studies confirm that our generated counterfactuals outperform unpaired examples in teaching perceptual expertise, showing the potential of generative models for specialized visual learning.
Visual Vibration Tomography: Estimating Interior Material Properties from Monocular Video
Apr 06, 2021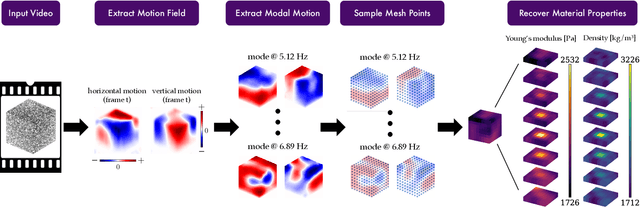

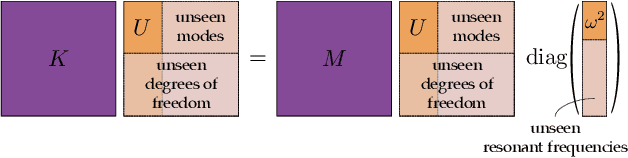
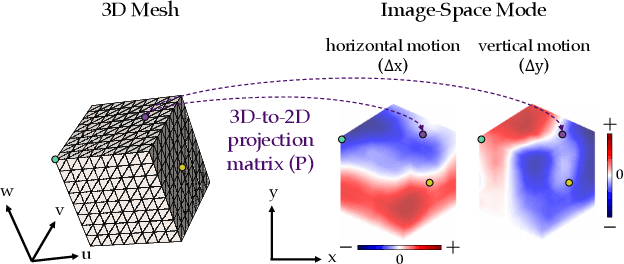
An object's interior material properties, while invisible to the human eye, determine motion observed on its surface. We propose an approach that estimates heterogeneous material properties of an object directly from a monocular video of its surface vibrations. Specifically, we estimate Young's modulus and density throughout a 3D object with known geometry. Knowledge of how these values change across the object is useful for characterizing defects and simulating how the object will interact with different environments. Traditional non-destructive testing approaches, which generally estimate homogenized material properties or the presence of defects, are expensive and use specialized instruments. We propose an approach that leverages monocular video to (1) measure and object's sub-pixel motion and decompose this motion into image-space modes, and (2) directly infer spatially-varying Young's modulus and density values from the observed image-space modes. On both simulated and real videos, we demonstrate that our approach is able to image material properties simply by analyzing surface motion. In particular, our method allows us to identify unseen defects on a 2D drum head from real, high-speed video.
Towards Unique and Informative Captioning of Images
Sep 08, 2020


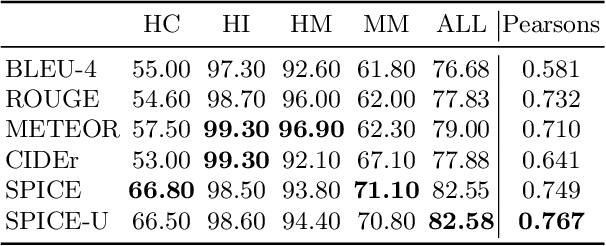
Despite considerable progress, state of the art image captioning models produce generic captions, leaving out important image details. Furthermore, these systems may even misrepresent the image in order to produce a simpler caption consisting of common concepts. In this paper, we first analyze both modern captioning systems and evaluation metrics through empirical experiments to quantify these phenomena. We find that modern captioning systems return higher likelihoods for incorrect distractor sentences compared to ground truth captions, and that evaluation metrics like SPICE can be 'topped' using simple captioning systems relying on object detectors. Inspired by these observations, we design a new metric (SPICE-U) by introducing a notion of uniqueness over the concepts generated in a caption. We show that SPICE-U is better correlated with human judgements compared to SPICE, and effectively captures notions of diversity and descriptiveness. Finally, we also demonstrate a general technique to improve any existing captioning model -- by using mutual information as a re-ranking objective during decoding. Empirically, this results in more unique and informative captions, and improves three different state-of-the-art models on SPICE-U as well as average score over existing metrics.