 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unique and Informative Captioning of Images
Paper and Code



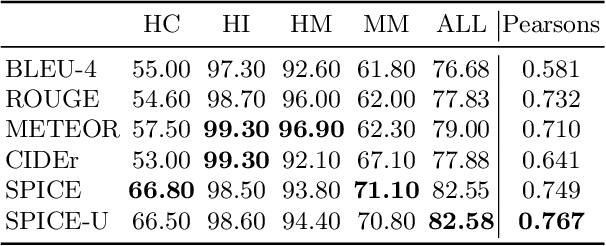
Despite considerable progress, state of the art image captioning models produce generic captions, leaving out important image details. Furthermore, these systems may even misrepresent the image in order to produce a simpler caption consisting of common concepts. In this paper, we first analyze both modern captioning systems and evaluation metrics through empirical experiments to quantify these phenomena. We find that modern captioning systems return higher likelihoods for incorrect distractor sentences compared to ground truth captions, and that evaluation metrics like SPICE can be 'topped' using simple captioning systems relying on object detectors. Inspired by these observations, we design a new metric (SPICE-U) by introducing a notion of uniqueness over the concepts generated in a caption. We show that SPICE-U is better correlated with human judgements compared to SPICE, and effectively captures notions of diversity and descriptiveness. Finally, we also demonstrate a general technique to improve any existing captioning model -- by using mutual information as a re-ranking objective during decoding. Empirically, this results in more unique and informative captions, and improves three different state-of-the-art models on SPICE-U as well as average score over existing metrics.