 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysarum Powered Differentiable Linear Programming Layers and Applications
Paper and Code


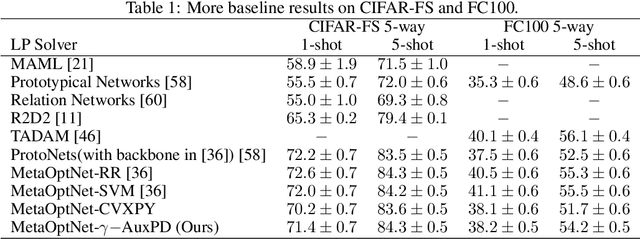
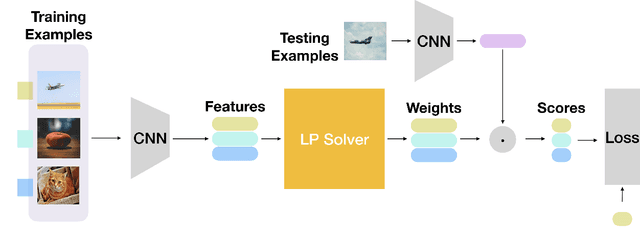
Consider a learning algorithm, which involves an internal call to an optimization routine such as a generalized eigenvalue problem, a cone programming problem or even sorting. Integrating such a method as layers within a trainable deep network in a numerically stable way is not simple -- for instance, only recently, strategies have emerged for eigendecomposition and differentiable sorting. We propose an efficient and differentiable solver for general linear programming problems which can be used in a plug and play manner within deep neural networks as a layer. Our development is inspired by a fascinating but not widely used link between dynamics of slime mold (physarum) and mathematical optimization schemes such as steepest descent. We describe our development and demonstrate the use of our solver in a video object segmentation task and meta-learning for few-shot learning. We review the relevant known results and provide a technical analysis describing its applicability for our use cases. Our solver performs comparably with a customized projected gradient descent method on the first task and outperforms the very recently proposed differentiable CVXPY solver on the second task. Experiments show that our solver converges quickly without the need for a feasible initial point. Interestingly, our scheme is easy to implement and can easily serve as layers whenever a learning procedure needs a fast approximate solution to a LP, within a larger network.