 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Temporal Transformations From Time-Lapse Videos
Paper and Code
Aug 27, 2016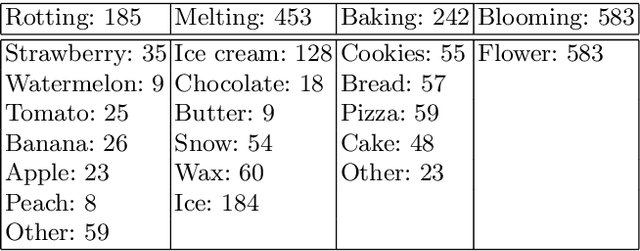



Based on life-long observations of physical, chemical, and biologic phenomena in the natural world, humans can often easily picture in their minds what an object will look like in the future. But, what about computers? In this paper, we learn computational models of object transformations from time-lapse videos. In particular, we explore the use of generative models to create depictions of objects at future times. These models explore several different prediction tasks: generating a future state given a single depiction of an object, generating a future state given two depictions of an object at different times, and generating future states recursively in a recurrent framework. We provide both qualitative and quantitative evaluations of the generated results, and also conduct a human evaluation to compare variations of our models.