 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage2GIF: Generating Cinemagraphs using Recurrent Deep Q-Networks
Paper and Code
Jan 27, 2018

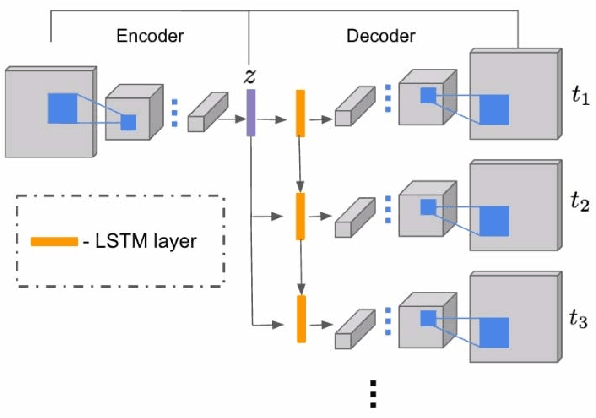

Given a still photograph, one can imagine how dynamic objects might move against a static background. This idea has been actualized in the form of cinemagraphs, where the motion of particular objects within a still image is repeated, giving the viewer a sense of animation. In this paper, we learn computational models that can generate cinemagraph sequences automatically given a single image. To generate cinemagraphs, we explore combining generative models with a recurrent neural network and deep Q-networks to enhance the power of sequence generation. To enable and evaluate these models we make use of two datasets, one synthetically generated and the other containing real video generated cinemagraphs. Both qualitative and quantitative evaluations demonstrate the effectiveness of our models on the synthetic and real datasets.