 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness, Evaluation and Adaptation of Machine Learning Models in the Wild
Paper and Code


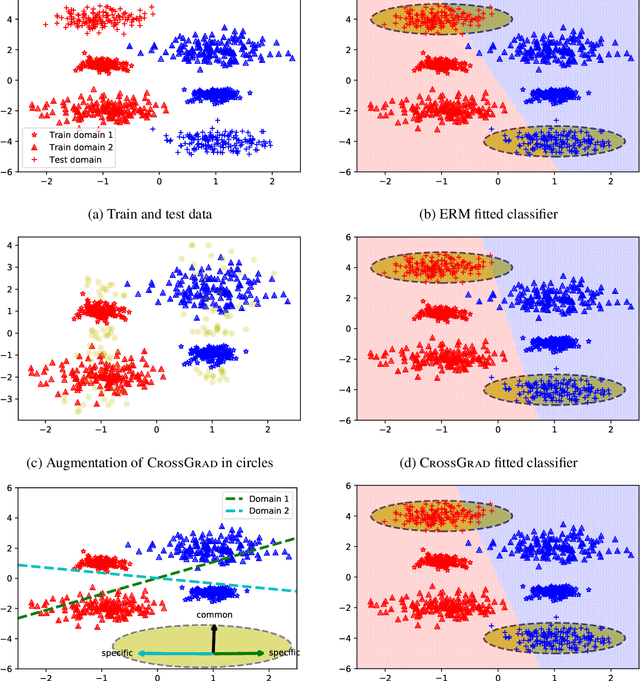
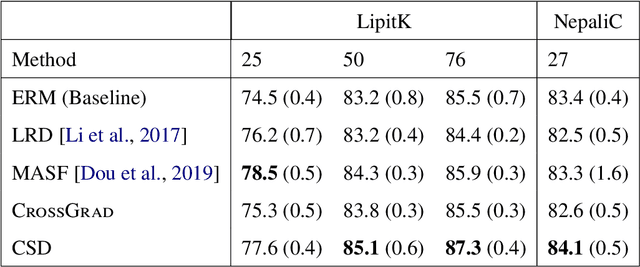
Our goal is to improve reliability of Machine Learning (ML) systems deployed in the wild. ML models perform exceedingly well when test examples are similar to train examples. However, real-world applications are required to perform on any distribution of test examples. Current ML systems can fail silently on test examples with distribution shifts. In order to improve reliability of ML models due to covariate or domain shift, we propose algorithms that enable models to: (a) generalize to a larger family of test distributions, (b) evaluate accuracy under distribution shifts, (c) adapt to a target distribution. We study causes of impaired robustness to domain shifts and present algorithms for training domain robust models. A key source of model brittleness is due to domain overfitting, which our new training algorithms suppress and instead encourage domain-general hypotheses. While we improve robustness over standard training methods for certain problem settings, performance of ML systems can still vary drastically with domain shifts. It is crucial for developers and stakeholders to understand model vulnerabilities and operational ranges of input, which could be assessed on the fly during the deployment, albeit at a great cost. Instead, we advocate for proactively estimating accuracy surfaces over any combination of prespecified and interpretable domain shifts for performance forecasting. We present a label-efficient estimation to address estimation over a combinatorial space of domain shifts. Further, when a model's performance on a target domain is found to be poor, traditional approaches adapt the model using the target domain's resources. Standard adaptation methods assume access to sufficient labeled resources, which may be impractical for deployed models. We initiate a study of lightweight adaptation techniques with only unlabeled data resources with a focus on language applications.