 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech bandwidth extension with WaveNet
Paper and Code
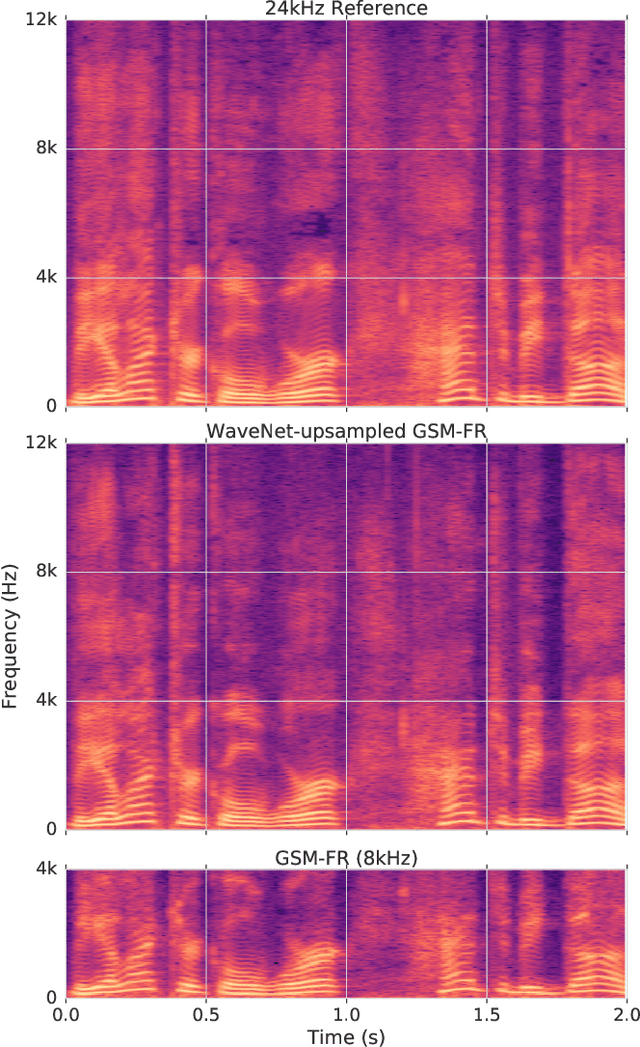
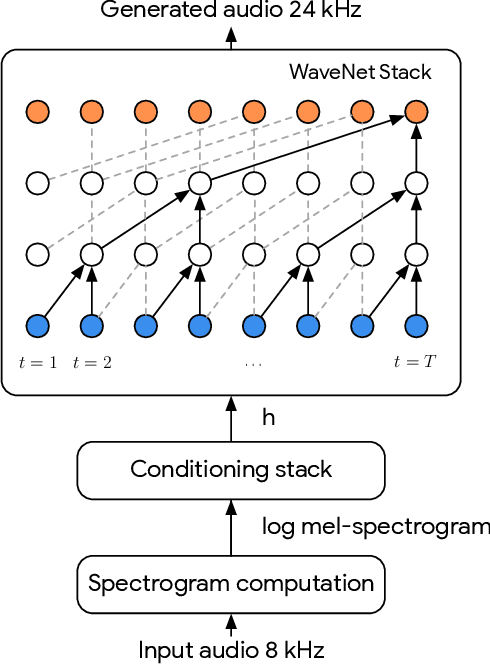
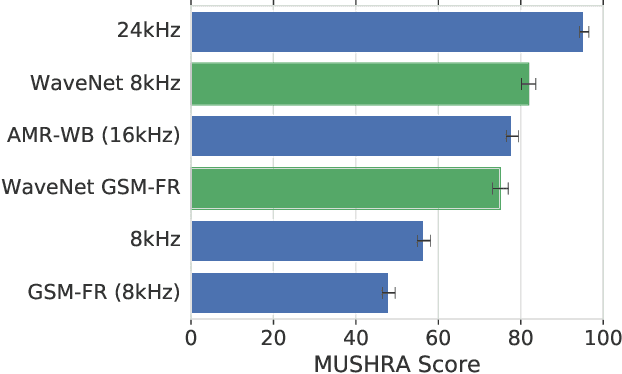
Large-scale mobile communication systems tend to contain legacy transmission channels with narrowband bottlenecks, resulting in characteristic "telephone-quality" audio. While higher quality codecs exist, due to the scale and heterogeneity of the networks, transmitting higher sample rate audio with modern high-quality audio codecs can be difficult in practice. This paper proposes an approach where a communication node can instead extend the bandwidth of a band-limited incoming speech signal that may have been passed through a low-rate codec. To this end, we propose a WaveNet-based model conditioned on a log-mel spectrogram representation of a bandwidth-constrained speech audio signal of 8 kHz and audio with artifacts from GSM full-rate (FR) compression to reconstruct the higher-resolution signal. In our experimental MUSHRA evaluation, we show that a model trained to upsample to 24kHz speech signals from audio passed through the 8kHz GSM-FR codec is able to reconstruct audio only slightly lower in quality to that of the Adaptive Multi-Rate Wideband audio codec (AMR-WB) codec at 16kHz, and closes around half the gap in perceptual quality between the original encoded signal and the original speech sampled at 24kHz. We further show that when the same model is passed 8kHz audio that has not been compressed, is able to again reconstruct audio of slightly better quality than 16kHz AMR-WB, in the same MUSHRA evaluation.