 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Aware Variational Thompson Sampling for Deep Q-Networks
Paper and Code
Feb 07, 2021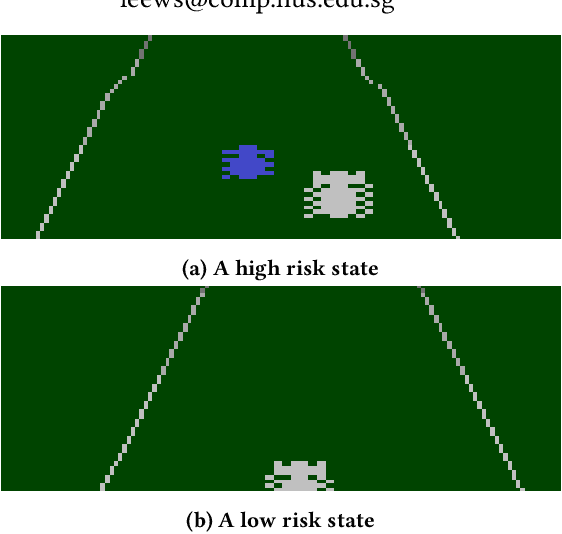
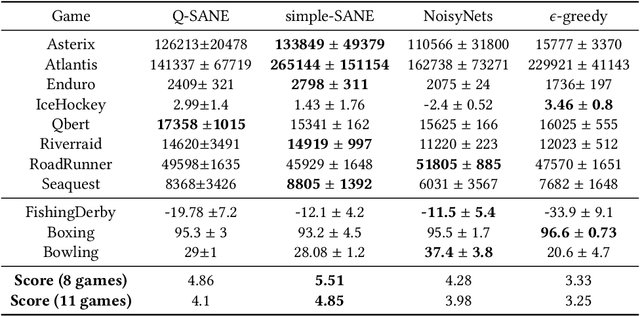
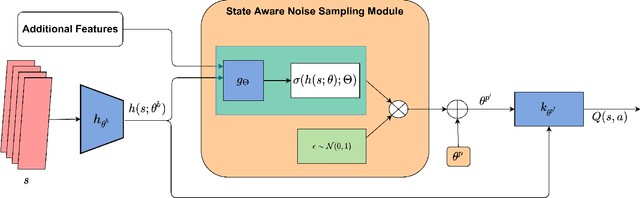
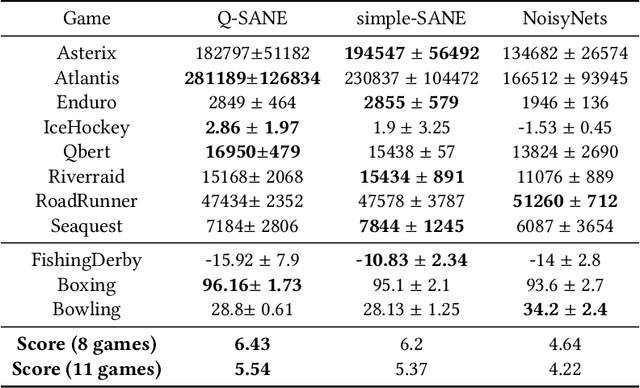
Thompson sampling is a well-known approach for balancing exploration and exploitation in reinforcement learning. It requires the posterior distribution of value-action functions to be maintained; this is generally intractable for tasks that have a high dimensional state-action space. We derive a variational Thompson sampling approximation for DQNs which uses a deep network whose parameters are perturbed by a learned variational noise distribution. We interpret the successful NoisyNets method \cite{fortunato2018noisy} as an approximation to the variational Thompson sampling method that we derive. Further, we propose State Aware Noisy Exploration (SANE) which seeks to improve on NoisyNets by allowing a non-uniform perturbation, where the amount of parameter perturbation is conditioned on the state of the agent. This is done with the help of an auxiliary perturbation module, whose output is state dependent and is learnt end to end with gradient descent. We hypothesize that such state-aware noisy exploration is particularly useful in problems where exploration in certain \textit{high risk} states may result in the agent failing badly. We demonstrate the effectiveness of the state-aware exploration method in the off-policy setting by augmenting DQNs with the auxiliary perturbation module.