 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVaDE : Event-Based Variational Thompson Sampling for Model-Based Reinforcement Learning
Jan 16, 2025



Posterior Sampling for Reinforcement Learning (PSRL) is a well-known algorithm that augments model-based reinforcement learning (MBRL) algorithms with Thompson sampling. PSRL maintains posterior distributions of the environment transition dynamics and the reward function, which are intractable for tasks with high-dimensional state and action spaces. Recent works show that dropout, used in conjunction with neural networks, induces variational distributions that can approximate these posteriors. In this paper, we propose Event-based Variational Distributions for Exploration (EVaDE), which are variational distributions that are useful for MBRL, especially when the underlying domain is object-based. We leverage the general domain knowledge of object-based domains to design three types of event-based convolutional layers to direct exploration. These layers rely on Gaussian dropouts and are inserted between the layers of the deep neural network model to help facilitate variational Thompson sampling. We empirically show the effectiveness of EVaDE-equipped Simulated Policy Learning (EVaDE-SimPLe) on the 100K Atari game suite.
Differentiable Tree Search in Latent State Space
Jan 22, 2024In decision-making problems with limited training data, policy functions approximated using deep neural networks often exhibit suboptimal performance. An alternative approach involves learning a world model from the limited data and determining actions through online search. However, the performance is adversely affected by compounding errors arising from inaccuracies in the learnt world model. While methods like TreeQN have attempted to address these inaccuracies by incorporating algorithmic structural biases into their architectures, the biases they introduce are often weak and insufficient for complex decision-making tasks. In this work, we introduce Differentiable Tree Search (DTS), a novel neural network architecture that significantly strengthens the inductive bias by embedding the algorithmic structure of a best-first online search algorithm. DTS employs a learnt world model to conduct a fully differentiable online search in latent state space. The world model is jointly optimised with the search algorithm, enabling the learning of a robust world model and mitigating the effect of model inaccuracies. We address potential Q-function discontinuities arising from naive incorporation of best-first search by adopting a stochastic tree expansion policy, formulating search tree expansion as a decision-making task, and introducing an effective variance reduction technique for the gradient computation. We evaluate DTS in an offline-RL setting with a limited training data scenario on Procgen games and grid navigation task, and demonstrate that DTS outperforms popular model-free and model-based baselines.
ExPoSe: Combining State-Based Exploration with Gradient-Based Online Search
Feb 04, 2022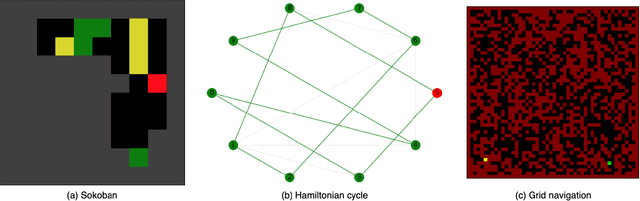


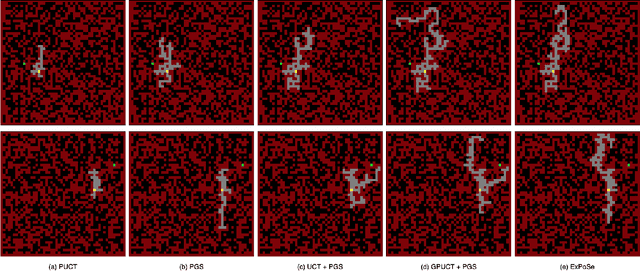
A tree-based online search algorithm iteratively simulates trajectories and updates Q-value information on a set of states represented by a tree structure. Alternatively, policy gradient based online search algorithms update the information obtained from simulated trajectories directly onto the parameters of the policy and has been found to be effective. While tree-based methods limit the updates from simulations to the states that exist in the tree and do not interpolate the information to nearby states, policy gradient search methods do not do explicit exploration. In this paper, we show that it is possible to combine and leverage the strengths of these two methods for improved search performance. We examine the key reasons behind the improvement and propose a simple yet effective online search method, named Exploratory Policy Gradient Search (ExPoSe), that updates both the parameters of the policy as well as search information on the states in the trajectory. We conduct experiments on complex planning problems, which include Sokoban and Hamiltonian cycle search in sparse graphs and show that combining exploration with policy gradient improves online search performance.