 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Multi-modal Memory Network for Movie Question Answering
Paper and Code
Nov 12, 2018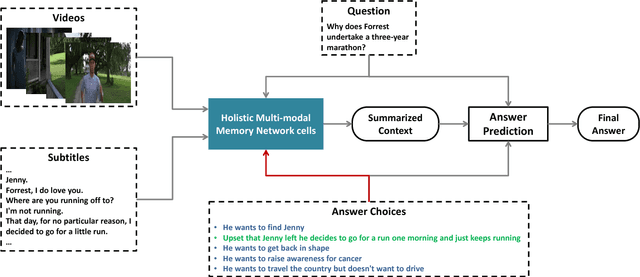
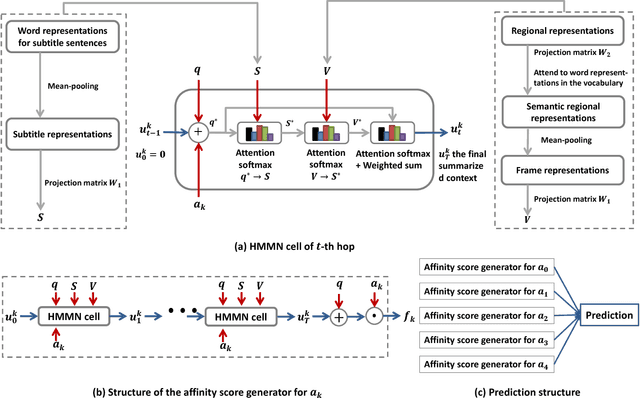
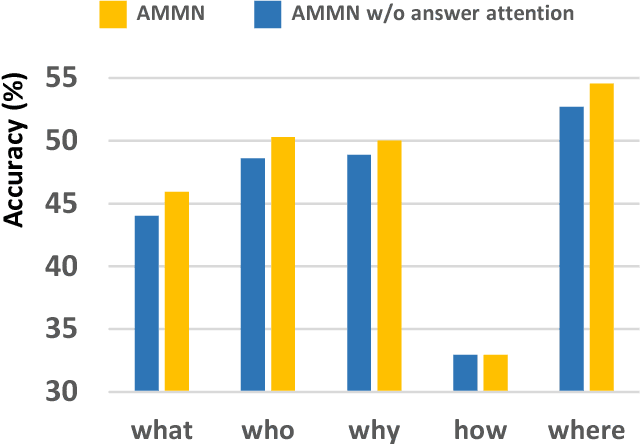
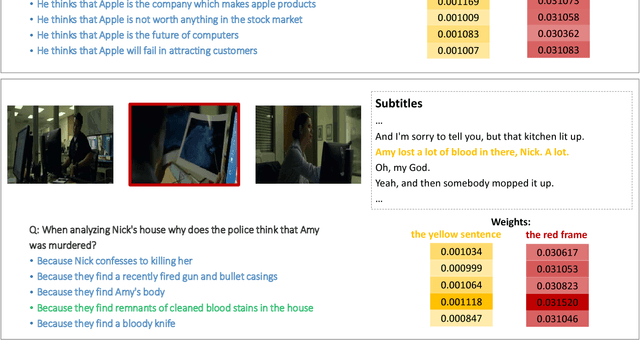
Answering questions according to multi-modal context is a challenging problem as it requires a deep integration of different data sources. Existing approaches only employ partial interactions among data sources in one attention hop. In this paper, we present the Holistic Multi-modal Memory Network (HMMN) framework which fully considers the interactions between different input sources (multi-modal context, question) in each hop. In addition, it takes answer choices into consideration during the context retrieval stage. Therefore, the proposed framework effectively integrates multi-modal context, question, and answer information, which leads to more informative context retrieved for question answering. Our HMMN framework achieves state-of-the-art accuracy on MovieQA dataset. Extensive ablation studies show the importance of holistic reasoning and contributions of different attention strategies.