 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Efficient Neural Networks Using Hessian Based Pruning
Paper and Code
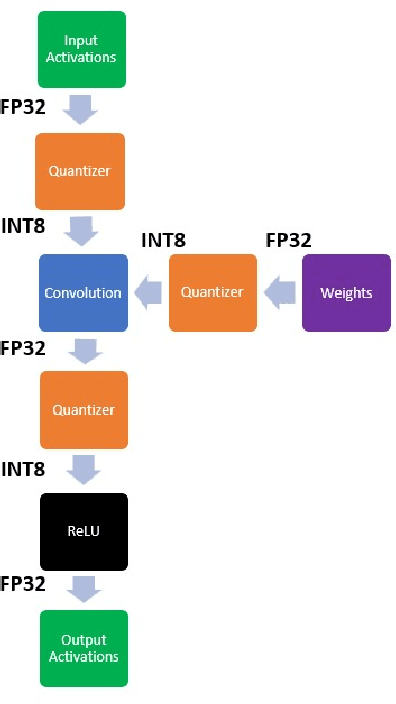
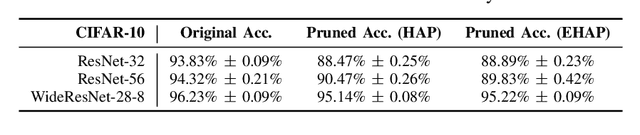

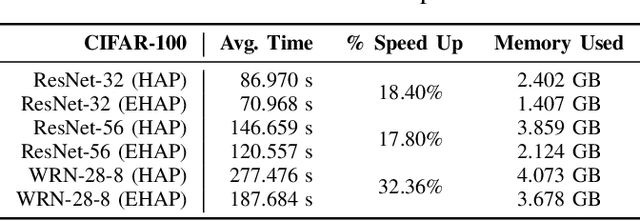
Neural network pruning is a practical way for reducing the size of trained models and the number of floating-point operations. One way of pruning is to use the relative Hessian trace to calculate sensitivity of each channel, as compared to the more common magnitude pruning approach. However, the stochastic approach used to estimate the Hessian trace needs to iterate over many times before it can converge. This can be time-consuming when used for larger models with many millions of parameters. To address this problem, we modify the existing approach by estimating the Hessian trace using FP16 precision instead of FP32. We test the modified approach (EHAP) on ResNet-32/ResNet-56/WideResNet-28-8 trained on CIFAR10/CIFAR100 image classification tasks and achieve faster computation of the Hessian trace. Specifically, our modified approach can achieve speed ups ranging from 17% to as much as 44% during our experiments on different combinations of model architectures and GPU devices. Our modified approach also takes up around 40% less GPU memory when pruning ResNet-32 and ResNet-56 models, which allows for a larger Hessian batch size to be used for estimating the Hessian trace. Meanwhile, we also present the results of pruning using both FP16 and FP32 Hessian trace calculation and show that there are no noticeable accuracy differences between the two. Overall, it is a simple and effective way to compute the relative Hessian trace faster without sacrificing on pruned model performance. We also present a full pipeline using EHAP and quantization aware training (QAT), using INT8 QAT to compress the network further after pruning. In particular, we use symmetric quantization for the weights and asymmetric quantization for the activations.