 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaRT: Parallel Learning Towards Robust and Transparent AI
Jan 24, 2022



This paper takes a parallel learning approach for robust and transparent AI. A deep neural network is trained in parallel on multiple tasks, where each task is trained only on a subset of the network resources. Each subset consists of network segments, that can be combined and shared across specific tasks. Tasks can share resources with other tasks, while having independent task-related network resources. Therefore, the trained network can share similar representations across various tasks, while also enabling independent task-related representations. The above allows for some crucial outcomes. (1) The parallel nature of our approach negates the issue of catastrophic forgetting. (2) The sharing of segments uses network resources more efficiently. (3) We show that the network does indeed use learned knowledge from some tasks in other tasks, through shared representations. (4) Through examination of individual task-related and shared representations, the model offers transparency in the network and in the relationships across tasks in a multi-task setting. Evaluation of the proposed approach against complex competing approaches such as Continual Learning, Neural Architecture Search, and Multi-task learning shows that it is capable of learning robust representations. This is the first effort to train a DL model on multiple tasks in parallel. Our code is available at https://github.com/MahsaPaknezhad/PaRT
Explaining Adversarial Vulnerability with a Data Sparsity Hypothesis
Mar 01, 2021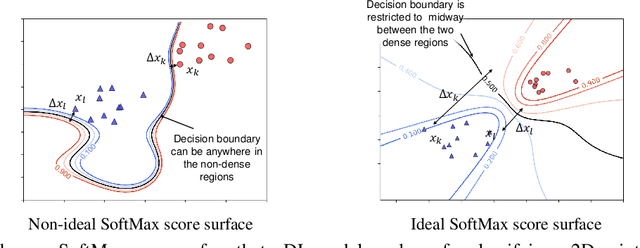
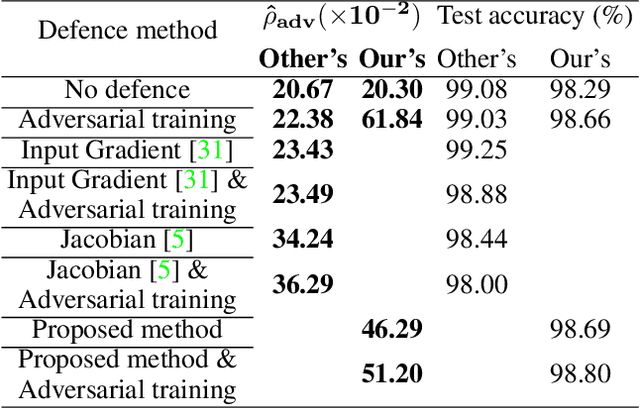
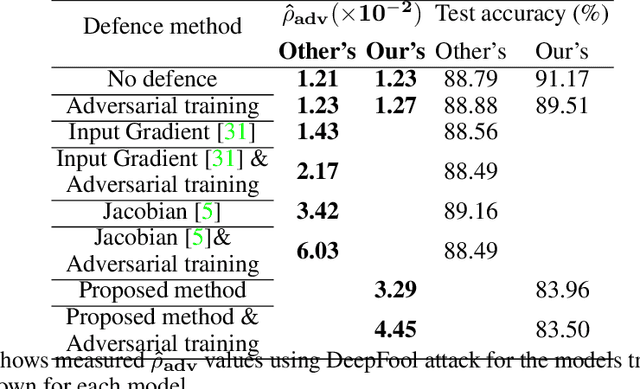
Despite many proposed algorithms to provide robustness to deep learning (DL) models, DL models remain susceptible to adversarial attacks. We hypothesize that the adversarial vulnerability of DL models stems from two factors. The first factor is data sparsity which is that in the high dimensional data space, there are large regions outside the support of the data distribution. The second factor is the existence of many redundant parameters in the DL models. Owing to these factors, different models are able to come up with different decision boundaries with comparably high prediction accuracy. The appearance of the decision boundaries in the space outside the support of the data distribution does not affect the prediction accuracy of the model. However, they make an important difference in the adversarial robustness of the model. We propose that the ideal decision boundary should be as far as possible from the support of the data distribution.\par In this paper, we develop a training framework for DL models to learn such decision boundaries spanning the space around the class distributions further from the data points themselves. Semi-supervised learning was deployed to achieve this objective by leveraging unlabeled data generated in the space outside the support of the data distribution. We measure adversarial robustness of the models trained using this training framework against well-known adversarial attacks We found that our results, other regularization methods and adversarial training also support our hypothesis of data sparcity. We show that the unlabeled data generated by noise using our framework is almost as effective as unlabeled data, sourced from existing data sets or generated by synthesis algorithms, on adversarial robustness. Our code is available at https://github.com/MahsaPaknezhad/AdversariallyRobustTraining.
Regional Registration of Whole Slide Image Stacks Containing Highly Deformed Artefacts
Feb 28, 2020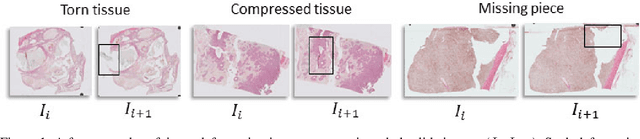

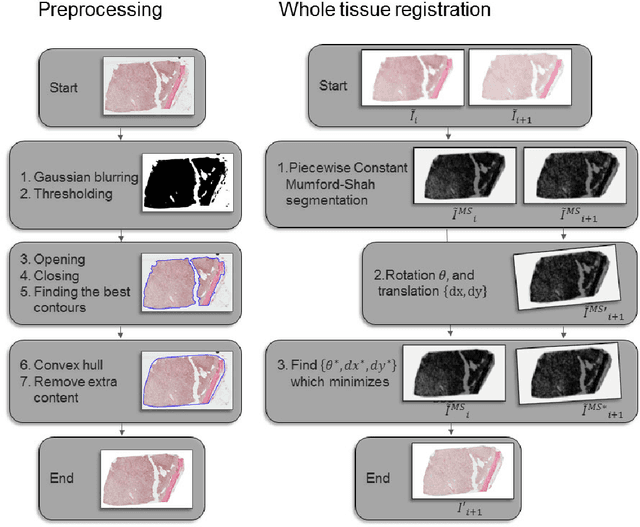
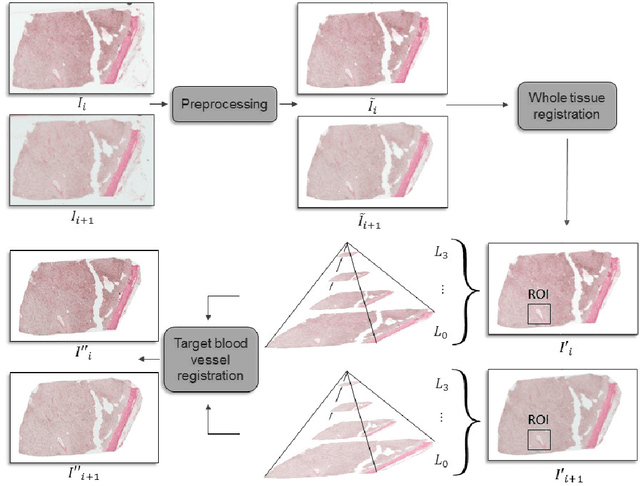
Motivation: High resolution 2D whole slide imaging provides rich information about the tissue structure. This information can be a lot richer if these 2D images can be stacked into a 3D tissue volume. A 3D analysis, however, requires accurate reconstruction of the tissue volume from the 2D image stack. This task is not trivial due to the distortions that each individual tissue slice experiences while cutting and mounting the tissue on the glass slide. Performing registration for the whole tissue slices may be adversely affected by the deformed tissue regions. Consequently, regional registration is found to be more effective. In this paper, we propose an accurate and robust regional registration algorithm for whole slide images which incrementally focuses registration on the area around the region of interest. Results: Using mean similarity index as the metric, the proposed algorithm (mean $\pm$ std: $0.84 \pm 0.11$) followed by a fine registration algorithm ($0.86 \pm 0.08$) outperformed the state-of-the-art linear whole tissue registration algorithm ($0.74 \pm 0.19$) and the regional version of this algorithm ($0.81 \pm 0.15$). The proposed algorithm also outperforms the state-of-the-art nonlinear registration algorithm (original : $0.82 \pm 0.12$, regional : $0.77 \pm 0.22$) for whole slide images and a recently proposed patch-based registration algorithm (patch size 256: $0.79 \pm 0.16$ , patch size 512: $0.77 \pm 0.16$) for medical images. Availability: The C++ implementation code is available online at the github repository: https://github.com/MahsaPaknezhad/WSIRegistration