 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Visual Words with Deep Features -- Patch Classification Model for Limited Dataset of Breast Tumours
Feb 22, 2022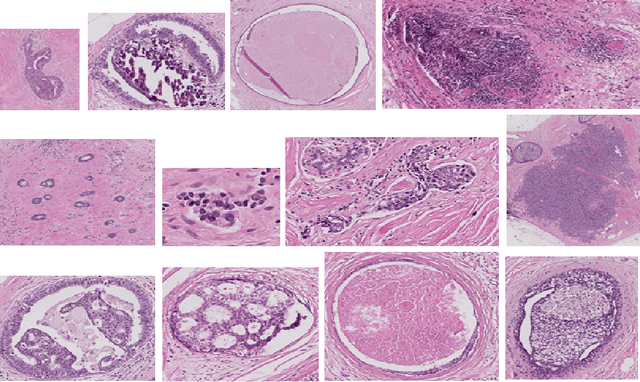
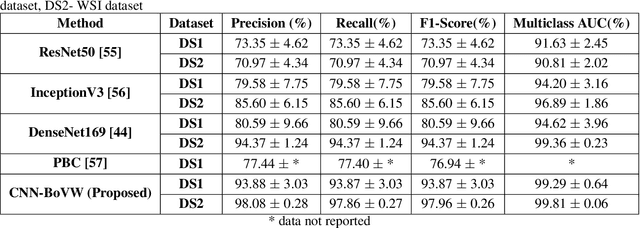
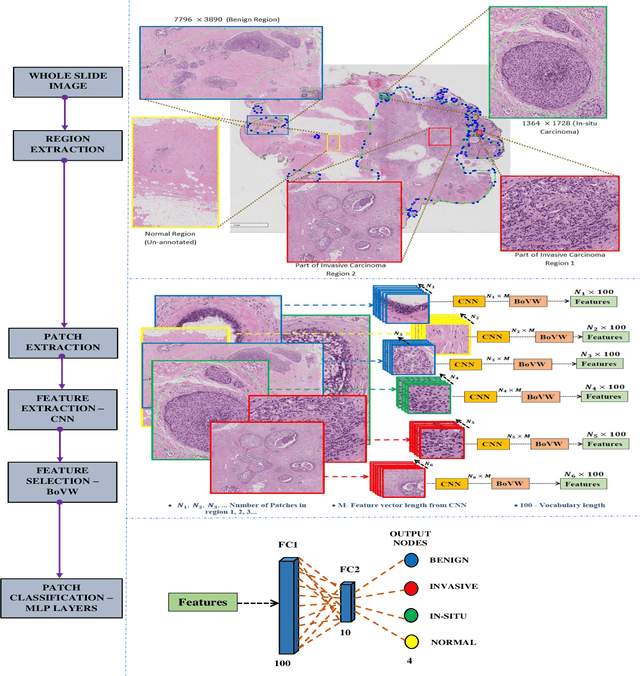
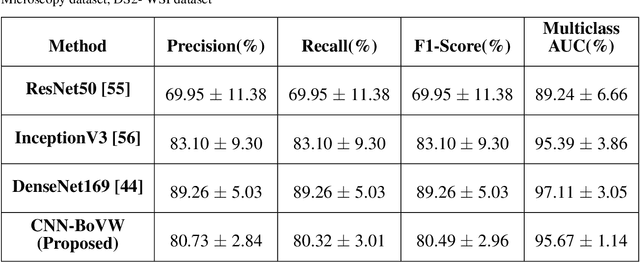
Currently, the computational complexity limits the training of high resolution gigapixel images using Convolutional Neural Networks. Therefore, such images are divided into patches or tiles. Since, these high resolution patches are encoded with discriminative information therefore; CNNs are trained on these patches to perform patch-level predictions. However, the problem with patch-level prediction is that pathologist generally annotates at image-level and not at patch level. Due to this limitation most of the patches may not contain enough class-relevant features. Through this work, we tried to incorporate patch descriptive capability within the deep framework by using Bag of Visual Words (BoVW) as a kind of regularisation to improve generalizability. Using this hypothesis, we aim to build a patch based classifier to discriminate between four classes of breast biopsy image patches (normal, benign, \textit{In situ} carcinoma, invasive carcinoma). The task is to incorporate quality deep features using CNN to describe relevant information in the images while simultaneously discarding irrelevant information using Bag of Visual Words (BoVW). The proposed method passes patches obtained from WSI and microscopy images through pre-trained CNN to extract features. BoVW is used as a feature selector to select most discriminative features among the CNN features. Finally, the selected feature sets are classified as one of the four classes. The hybrid model provides flexibility in terms of choice of pre-trained models for feature extraction. The pipeline is end-to-end since it does not require post processing of patch predictions to select discriminative patches. We compared our observations with state-of-the-art methods like ResNet50, DenseNet169, and InceptionV3 on the BACH-2018 challenge dataset. Our proposed method shows better performance than all the three methods.
PaRT: Parallel Learning Towards Robust and Transparent AI
Jan 24, 2022



This paper takes a parallel learning approach for robust and transparent AI. A deep neural network is trained in parallel on multiple tasks, where each task is trained only on a subset of the network resources. Each subset consists of network segments, that can be combined and shared across specific tasks. Tasks can share resources with other tasks, while having independent task-related network resources. Therefore, the trained network can share similar representations across various tasks, while also enabling independent task-related representations. The above allows for some crucial outcomes. (1) The parallel nature of our approach negates the issue of catastrophic forgetting. (2) The sharing of segments uses network resources more efficiently. (3) We show that the network does indeed use learned knowledge from some tasks in other tasks, through shared representations. (4) Through examination of individual task-related and shared representations, the model offers transparency in the network and in the relationships across tasks in a multi-task setting. Evaluation of the proposed approach against complex competing approaches such as Continual Learning, Neural Architecture Search, and Multi-task learning shows that it is capable of learning robust representations. This is the first effort to train a DL model on multiple tasks in parallel. Our code is available at https://github.com/MahsaPaknezhad/PaRT
Explaining Adversarial Vulnerability with a Data Sparsity Hypothesis
Mar 01, 2021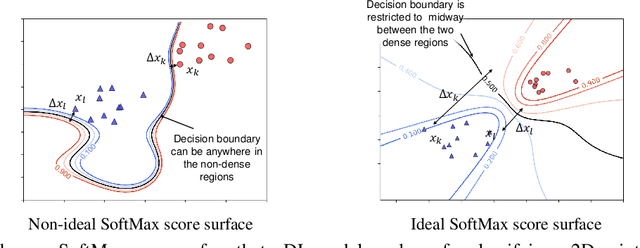
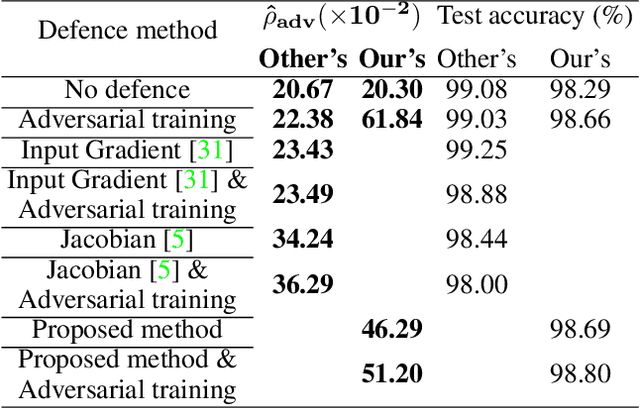
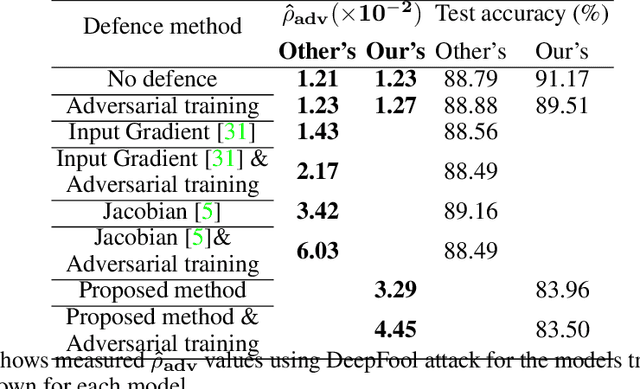
Despite many proposed algorithms to provide robustness to deep learning (DL) models, DL models remain susceptible to adversarial attacks. We hypothesize that the adversarial vulnerability of DL models stems from two factors. The first factor is data sparsity which is that in the high dimensional data space, there are large regions outside the support of the data distribution. The second factor is the existence of many redundant parameters in the DL models. Owing to these factors, different models are able to come up with different decision boundaries with comparably high prediction accuracy. The appearance of the decision boundaries in the space outside the support of the data distribution does not affect the prediction accuracy of the model. However, they make an important difference in the adversarial robustness of the model. We propose that the ideal decision boundary should be as far as possible from the support of the data distribution.\par In this paper, we develop a training framework for DL models to learn such decision boundaries spanning the space around the class distributions further from the data points themselves. Semi-supervised learning was deployed to achieve this objective by leveraging unlabeled data generated in the space outside the support of the data distribution. We measure adversarial robustness of the models trained using this training framework against well-known adversarial attacks We found that our results, other regularization methods and adversarial training also support our hypothesis of data sparcity. We show that the unlabeled data generated by noise using our framework is almost as effective as unlabeled data, sourced from existing data sets or generated by synthesis algorithms, on adversarial robustness. Our code is available at https://github.com/MahsaPaknezhad/AdversariallyRobustTraining.