 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch over Self-Edit Strategies for LLM Adaptation
Jan 20, 2026Many LLM-based open-ended search systems freeze the foundation model that proposes improvements to existing solutions, which may bottleneck long-run progress. Recent work has explored updating the proposal model at test time [arXiv:2511.23473], but the update strategy is still typically hand-specified. Therefore, this study investigated whether an LLM can use task feedback to decide how it should update its weights. For tractability, we focused on the simpler case where there is only one round of self-improvement, and restricted the update operator to self-supervised next token prediction (NTP), leaving the model freedom in choosing its training data and key NTP hyperparameters. Using the Self-Adapting Language Models (SEAL) [arXiv:2506.10943] framework as a testbed, we relaxed its fixed human template constraint and allowed the model to generate its own self-edit templates, thereby giving it more control over its training data and hyperparameters. Two variants were studied, differing in whether template generation was conditioned on a lightweight archive of past templates. In SEAL's Single-Passage Knowledge Incorporation setting with Qwen3-8B on SQuAD [arXiv:1606.05250], the no-archive variant performed comparably to the weaker "Implications" baseline, while the archive variant outperformed "Implications" and approached the strongest human-designed "Rewrite" baseline without surpassing it. Further analysis of collapse in the model's exploration revealed that a naive archive can confer some short-term robustness but can also accelerate homogenization, suggesting that explicit novelty pressure may be required to consistently advance beyond carefully optimized human strategies. Our code is available at https://github.com/cheongalc/search-self-edit-strategies .
Explaining Adversarial Vulnerability with a Data Sparsity Hypothesis
Mar 01, 2021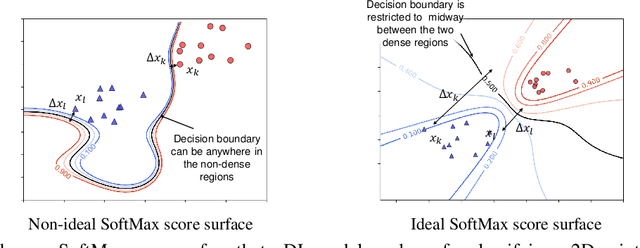
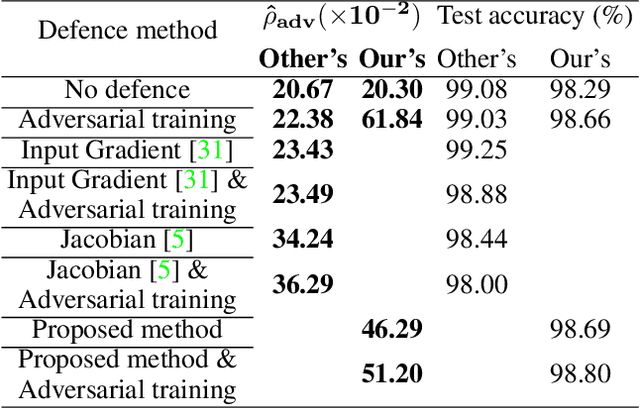
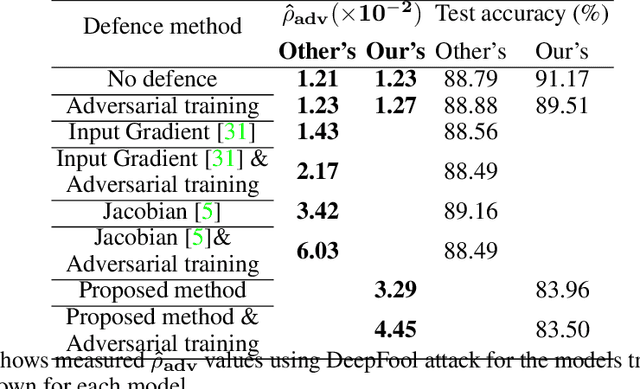
Despite many proposed algorithms to provide robustness to deep learning (DL) models, DL models remain susceptible to adversarial attacks. We hypothesize that the adversarial vulnerability of DL models stems from two factors. The first factor is data sparsity which is that in the high dimensional data space, there are large regions outside the support of the data distribution. The second factor is the existence of many redundant parameters in the DL models. Owing to these factors, different models are able to come up with different decision boundaries with comparably high prediction accuracy. The appearance of the decision boundaries in the space outside the support of the data distribution does not affect the prediction accuracy of the model. However, they make an important difference in the adversarial robustness of the model. We propose that the ideal decision boundary should be as far as possible from the support of the data distribution.\par In this paper, we develop a training framework for DL models to learn such decision boundaries spanning the space around the class distributions further from the data points themselves. Semi-supervised learning was deployed to achieve this objective by leveraging unlabeled data generated in the space outside the support of the data distribution. We measure adversarial robustness of the models trained using this training framework against well-known adversarial attacks We found that our results, other regularization methods and adversarial training also support our hypothesis of data sparcity. We show that the unlabeled data generated by noise using our framework is almost as effective as unlabeled data, sourced from existing data sets or generated by synthesis algorithms, on adversarial robustness. Our code is available at https://github.com/MahsaPaknezhad/AdversariallyRobustTraining.