 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Offensive Memes with Social Biases in Singapore Context Using Multimodal Large Language Models
Feb 25, 2025Traditional online content moderation systems struggle to classify modern multimodal means of communication, such as memes, a highly nuanced and information-dense medium. This task is especially hard in a culturally diverse society like Singapore, where low-resource languages are used and extensive knowledge on local context is needed to interpret online content. We curate a large collection of 112K memes labeled by GPT-4V for fine-tuning a VLM to classify offensive memes in Singapore context. We show the effectiveness of fine-tuned VLMs on our dataset, and propose a pipeline containing OCR, translation and a 7-billion parameter-class VLM. Our solutions reach 80.62% accuracy and 0.8192 AUROC on a held-out test set, and can greatly aid human in moderating online contents. The dataset, code, and model weights will be open-sourced at https://github.com/aliencaocao/vlm-for-memes-aisg.
Explaining Adversarial Vulnerability with a Data Sparsity Hypothesis
Mar 01, 2021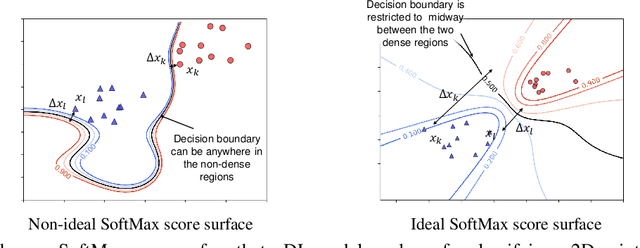
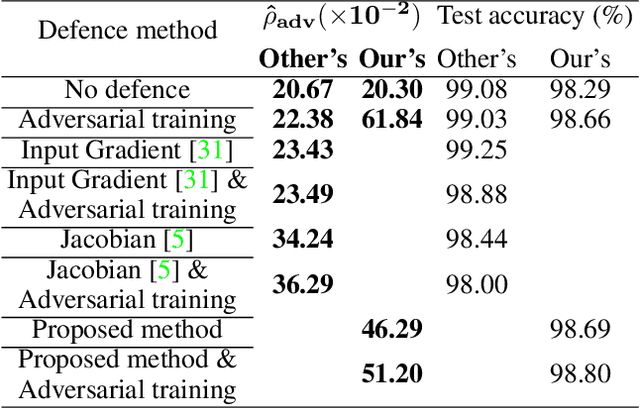
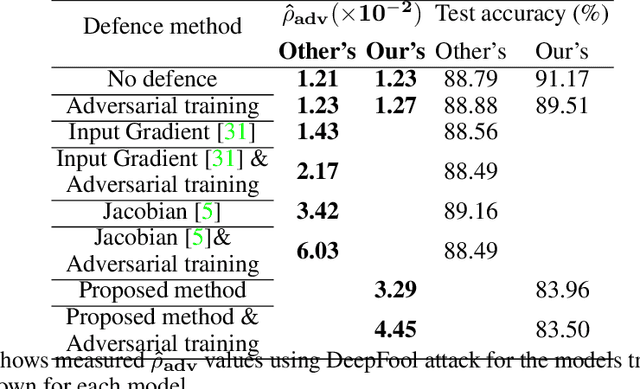
Despite many proposed algorithms to provide robustness to deep learning (DL) models, DL models remain susceptible to adversarial attacks. We hypothesize that the adversarial vulnerability of DL models stems from two factors. The first factor is data sparsity which is that in the high dimensional data space, there are large regions outside the support of the data distribution. The second factor is the existence of many redundant parameters in the DL models. Owing to these factors, different models are able to come up with different decision boundaries with comparably high prediction accuracy. The appearance of the decision boundaries in the space outside the support of the data distribution does not affect the prediction accuracy of the model. However, they make an important difference in the adversarial robustness of the model. We propose that the ideal decision boundary should be as far as possible from the support of the data distribution.\par In this paper, we develop a training framework for DL models to learn such decision boundaries spanning the space around the class distributions further from the data points themselves. Semi-supervised learning was deployed to achieve this objective by leveraging unlabeled data generated in the space outside the support of the data distribution. We measure adversarial robustness of the models trained using this training framework against well-known adversarial attacks We found that our results, other regularization methods and adversarial training also support our hypothesis of data sparcity. We show that the unlabeled data generated by noise using our framework is almost as effective as unlabeled data, sourced from existing data sets or generated by synthesis algorithms, on adversarial robustness. Our code is available at https://github.com/MahsaPaknezhad/AdversariallyRobustTraining.